Understanding how the human brain works is one of the key challenges that science and society face. The Algonauts challenge proposes a test of how well computational models do today. This test is intrinsically open and quantitative. This will allow us to precisely assess the progress in explaining the human brain.
At every instant, we are flooded by a massive amount of visual and auditory (sound and language) information - and yet, we perceive the world as ordered and meaningful actions, events and language. The primary target of the 2025 Challenge is predicting human brain responses to complex naturalistic multimodal movies, using the largest available brain dataset for this purpose.
Watching multimodal movies activates large swathes of the human cortex. We pose the question: How well does your computational model account for these activations?
Watch the first video above for an introduction to the Algonauts 2025 challenge, and the second video for a detailed walkthrough of the development kit. When you are ready to participate, the third video will guide you through the Codabench competition submission process.

The goal of the 2025 challenge is to provide a platform for biological and artificial intelligence scientists to cooperate and compete in developing cutting-edge brain encoding models. Specifically, these models should predict whole brain response to multimodal naturalistic stimulation, and generalize outside their training distribution.
The Challenge data is based on the CNeuroMod dataset which, as of now, most intensively samples single subject neural responses to a variety of naturalistic tasks, including movie watching. The CNeuroMod dataset’s unprecedented size, combined with the multimodal nature and diversity of its stimuli and tasks, makes it an ideal training and testing ground to build robust encoding models of fMRI responses to multimodal stimuli that generalize outside of their training distribution. Learn more about the stimuli and fMRI dataset used in the 2025 Challenge.
We provide:
With that, challenge participants are expected to build computational models to predict brain responses to in-distribution (ID) and out-of-distribution (OOD) movies for which the brain data are withheld.
Challenge participants submit predicted responses in the format described in the development kit. We score the submission by measuring the predictivity for each brain parcel for all the subjects and display on the leaderboard the overall mean predictivity over all parcels and subjects.
The challenge is hosted on Codabench, and consists of two main serial phases:
To enforce strict tests of OOD generalization during the model selection phase, the two phases are based on data from different distributions, and have separate leaderboards. The challenge will be followed by an indefinite post-challenge phase, which will serve as a public benchmark for anyone wishing to test brain encoding models on multimodal movie data (Figure 1).
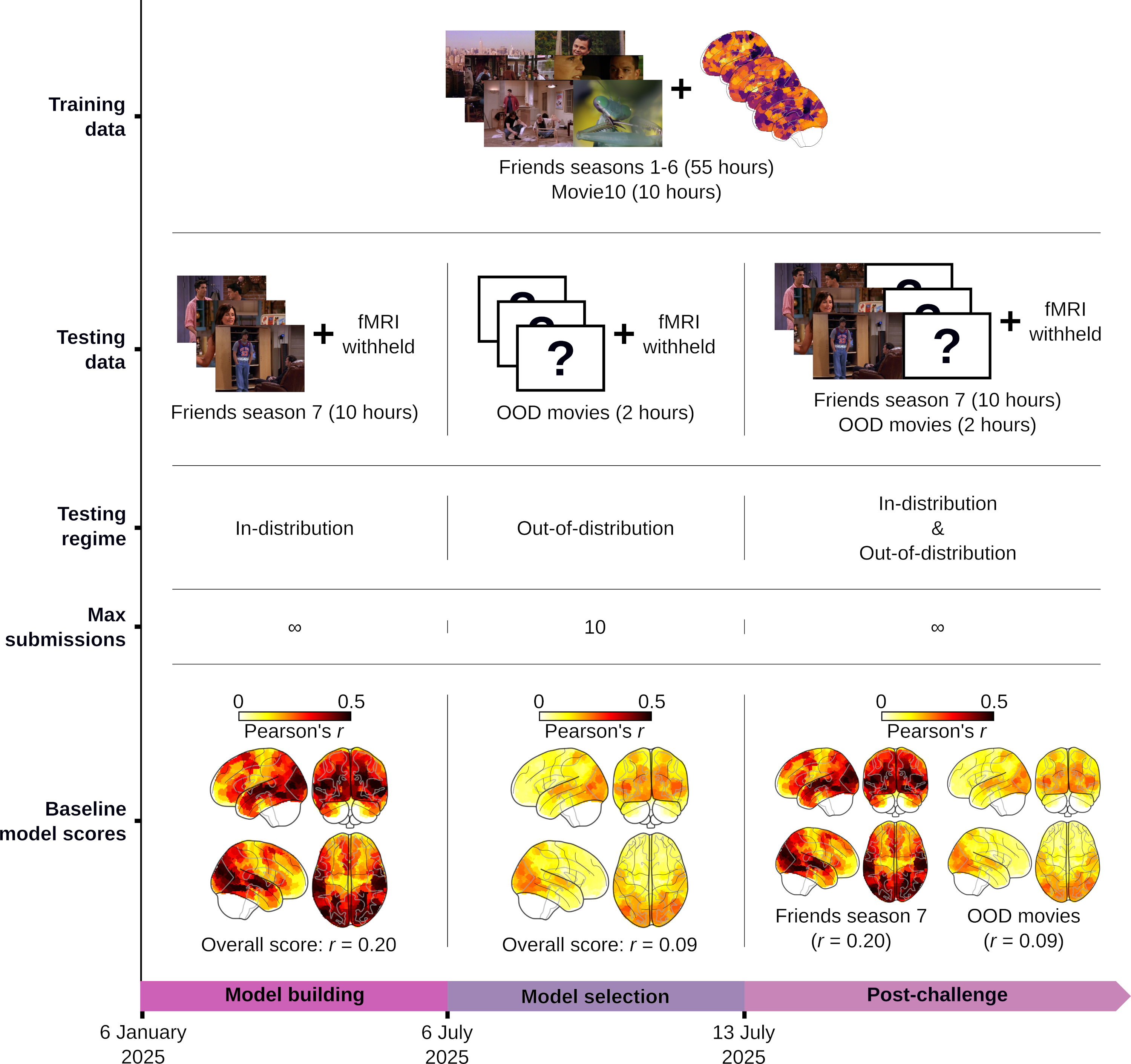
Figure 1 | Challenge phases. During the model building phase, models are trained using stimuli and corresponding fMRI responses for seasons 1 to 6 of the sitcom Friends and Movie10 (a set of four movies), and tested in-distribution (ID) on Friends season 7 (for which the fMRI responses are withheld) with unlimited submissions. During the model selection phase, the winning models are selected based on the accuracy of their predicted fMRI responses for out-of-distribution (OOD) movie stimuli (for which the fMRI responses are withheld) with up to ten submissions. The challenge will be followed by an indefinite post-challenge phase with unlimited submissions, which will serve as a public benchmark for both ID and OOD model validation.
During this first phase, challenge participants will train and test encoding models using movie stimuli and fMRI responses from the same distribution.
| Rank | Team Name | Challenge Score | Report | Code | Visualization |
|---|---|---|---|---|---|
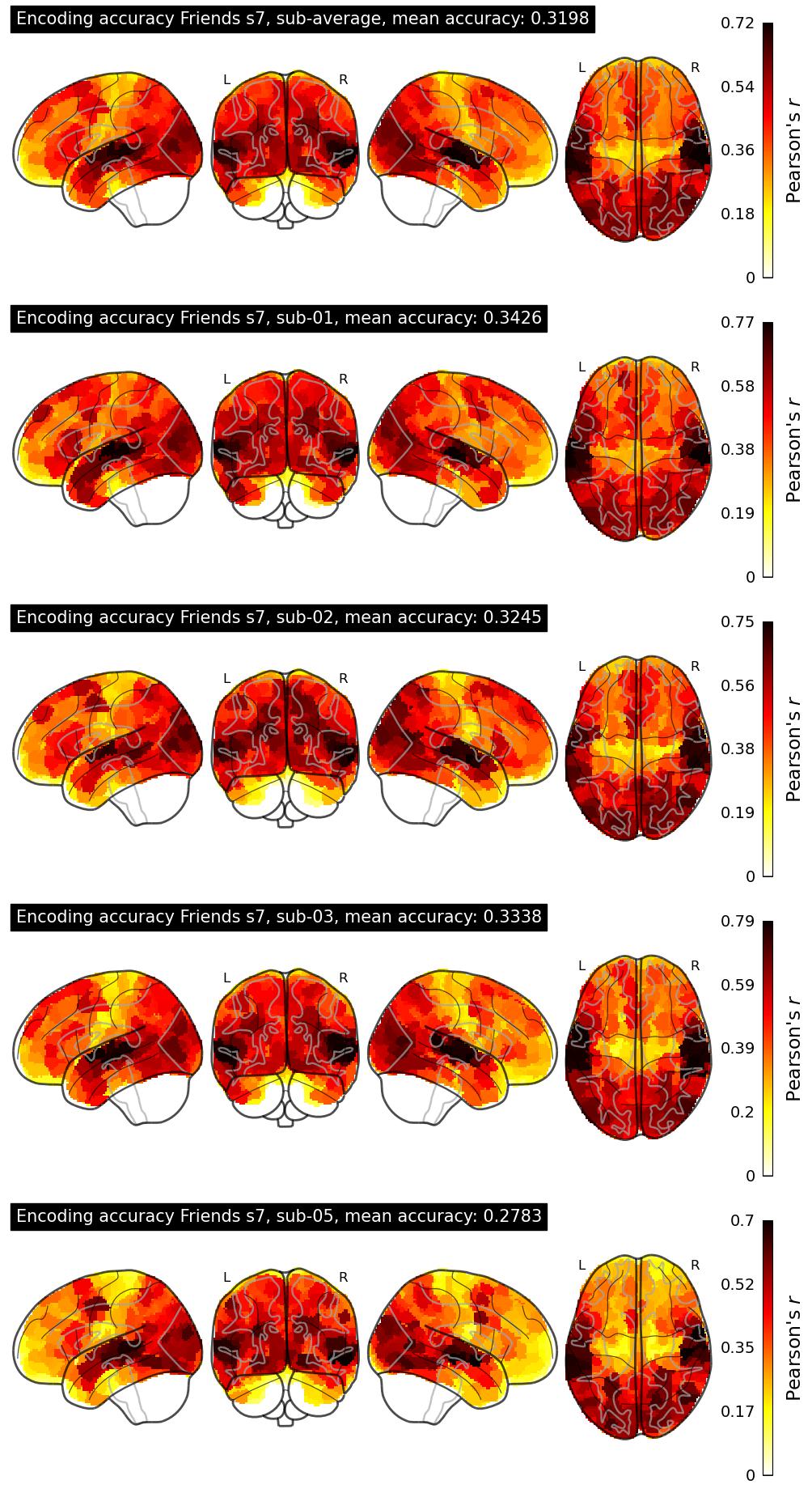
| 1 | NCG | 0.3198 | Visualization | ||
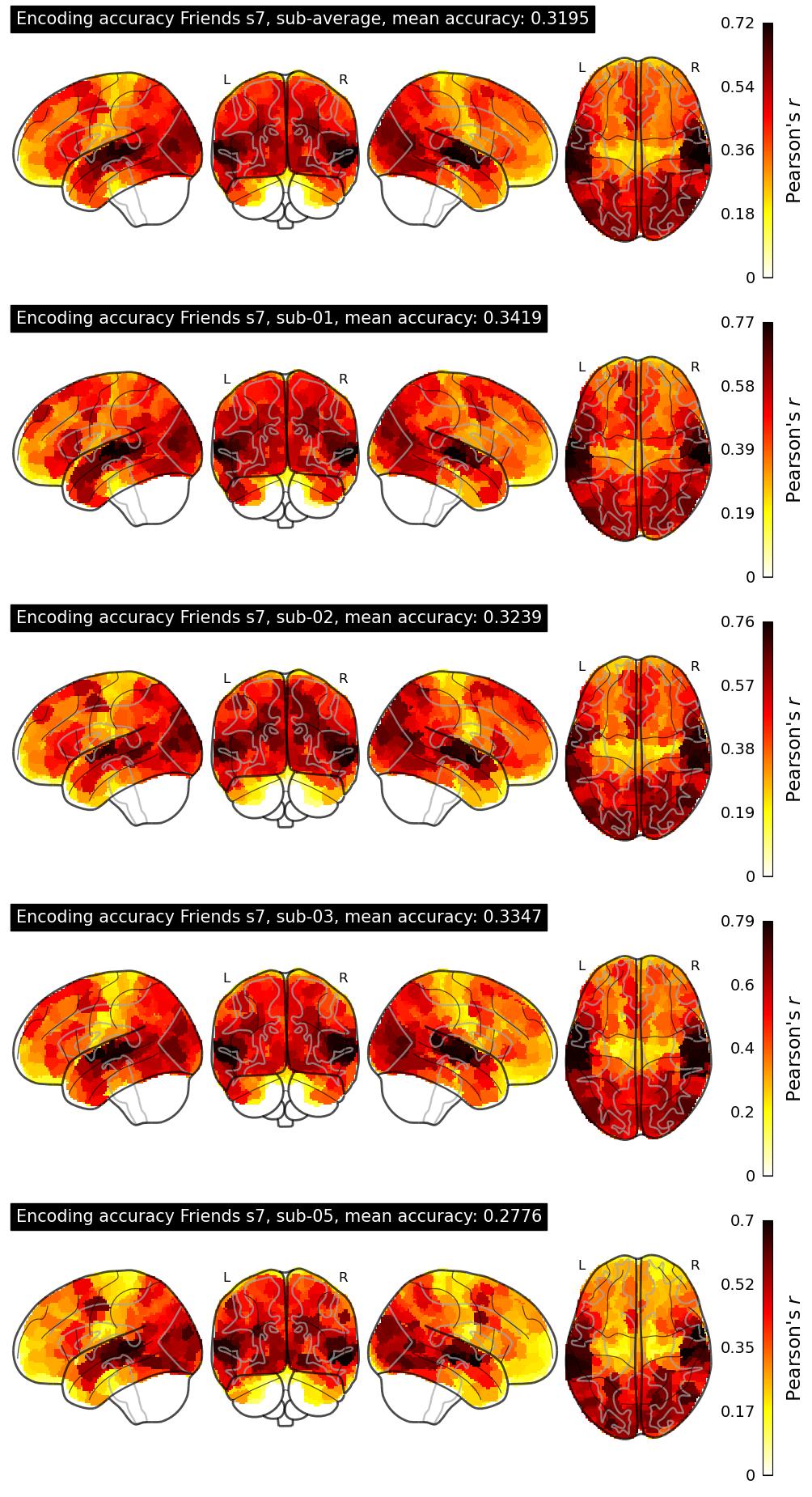
| 2 | sdascoli | 0.3195 | Visualization | ||
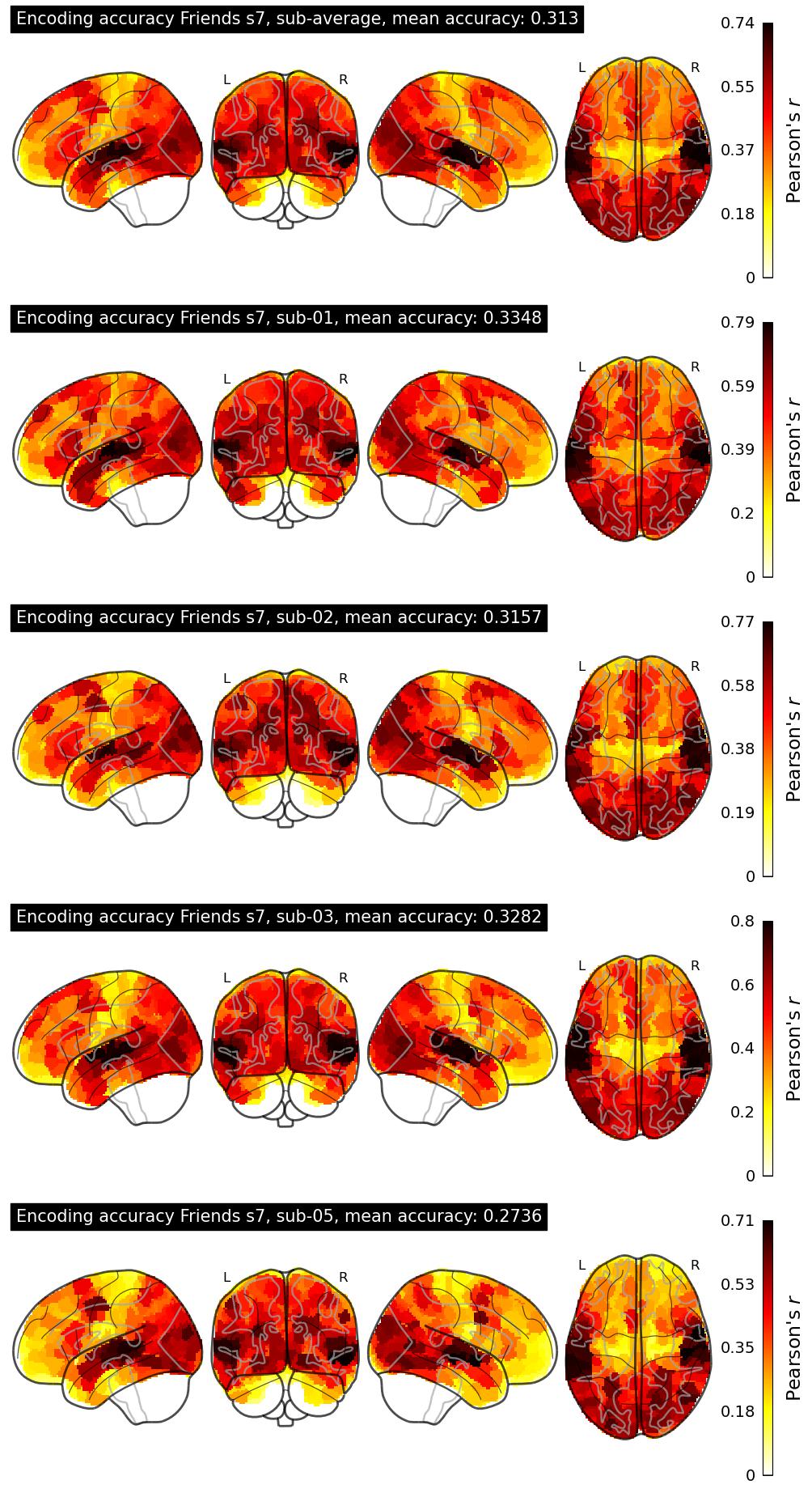
| 3 | SDA | 0.3130 | Visualization | ||
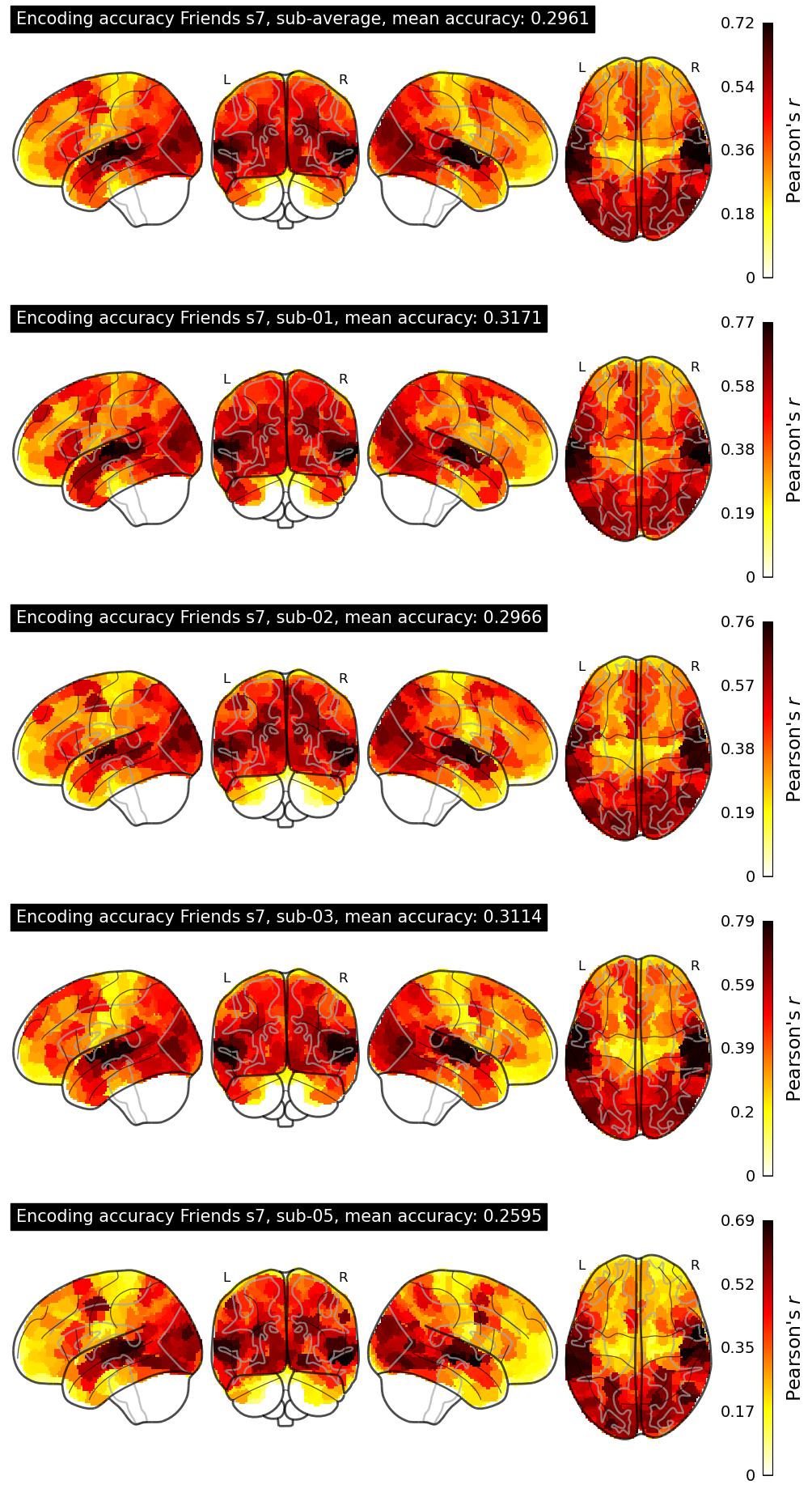
| 4 | angelneer926 | 0.2961 | Visualization | ||
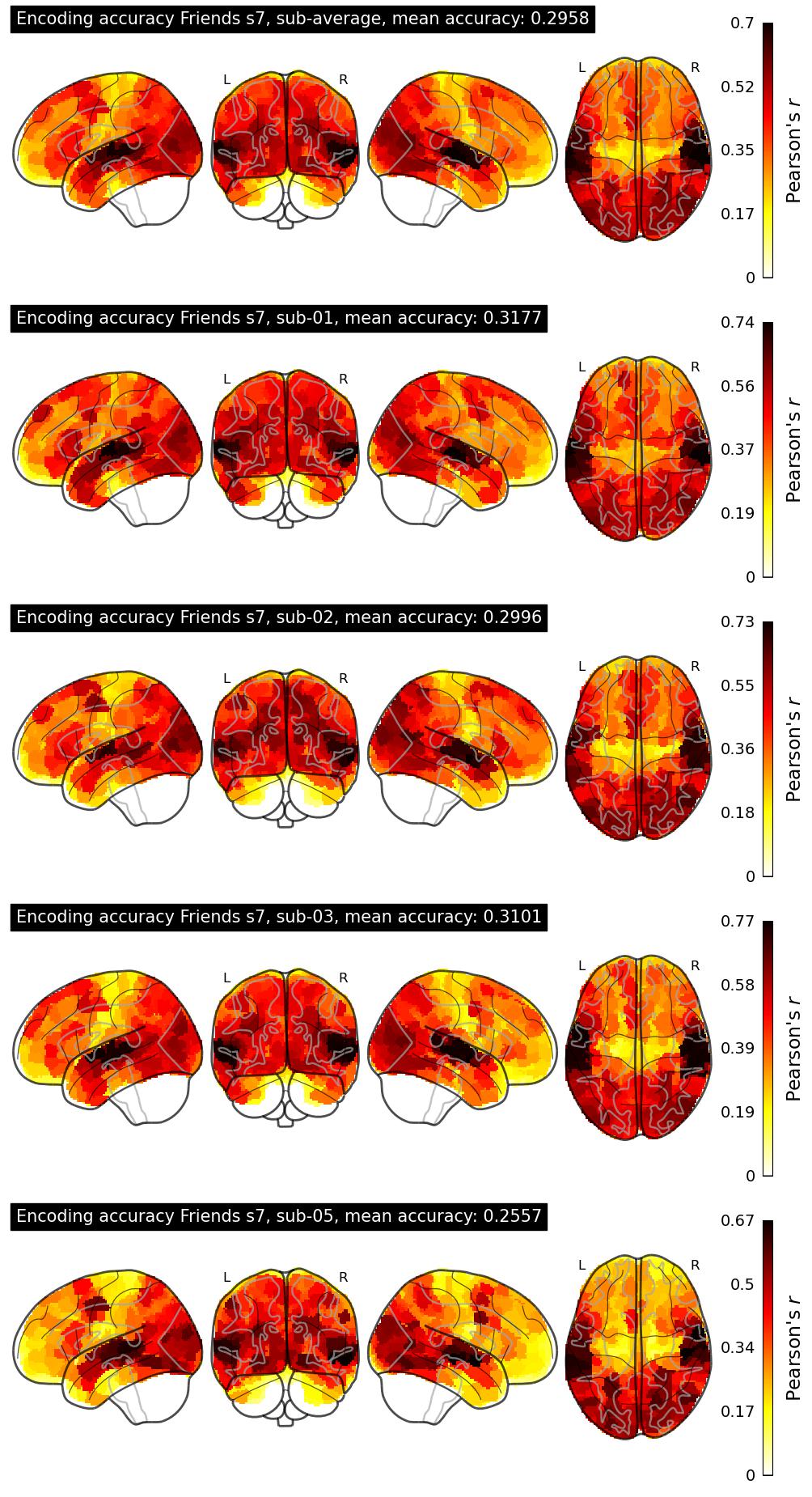
| 5 | CVIU-UARK | 0.2958 | Visualization | ||
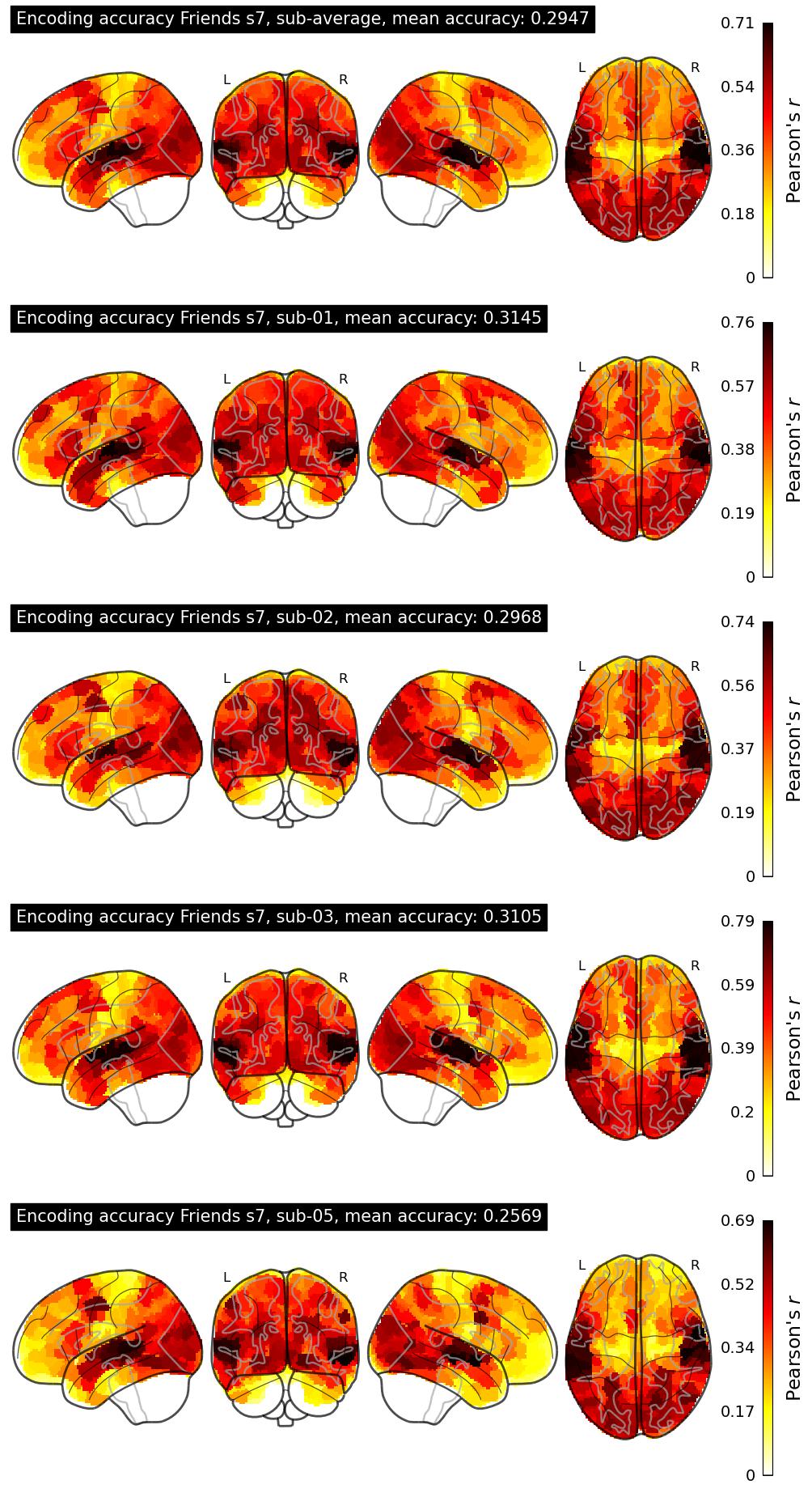
| 6 | VIL | 0.2947 | Visualization | ||
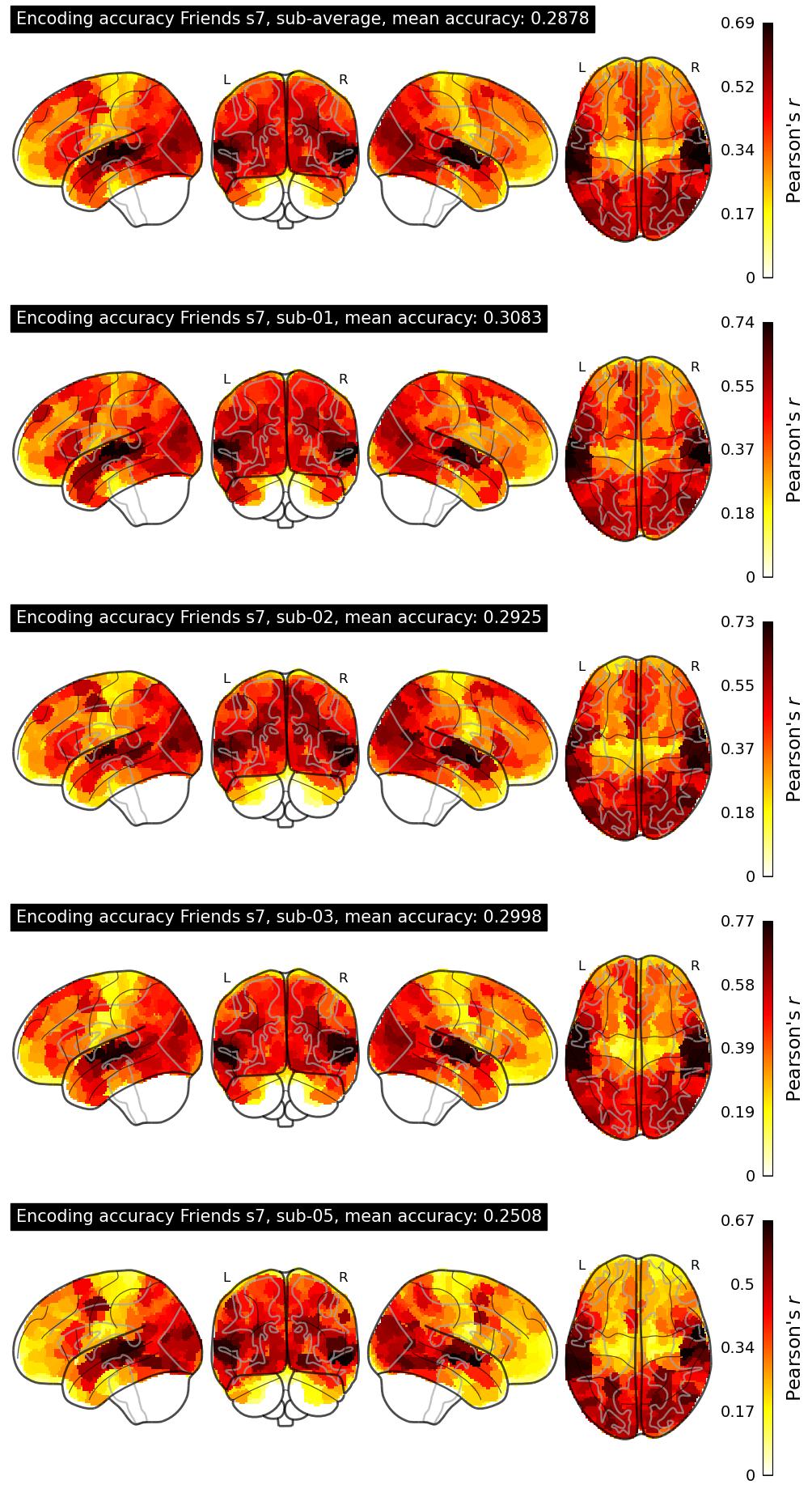
| 7 | MedARC | 0.2878 | Visualization | ||
| 8 | ckadirt | 0.2730 | Visualization | ||
| 9 | corsi01 | 0.2659 | Visualization | ||
| 10 | ICL_SNU | 0.2626 | Visualization | ||
| 11 | alit | 0.2622 | Visualization | ||
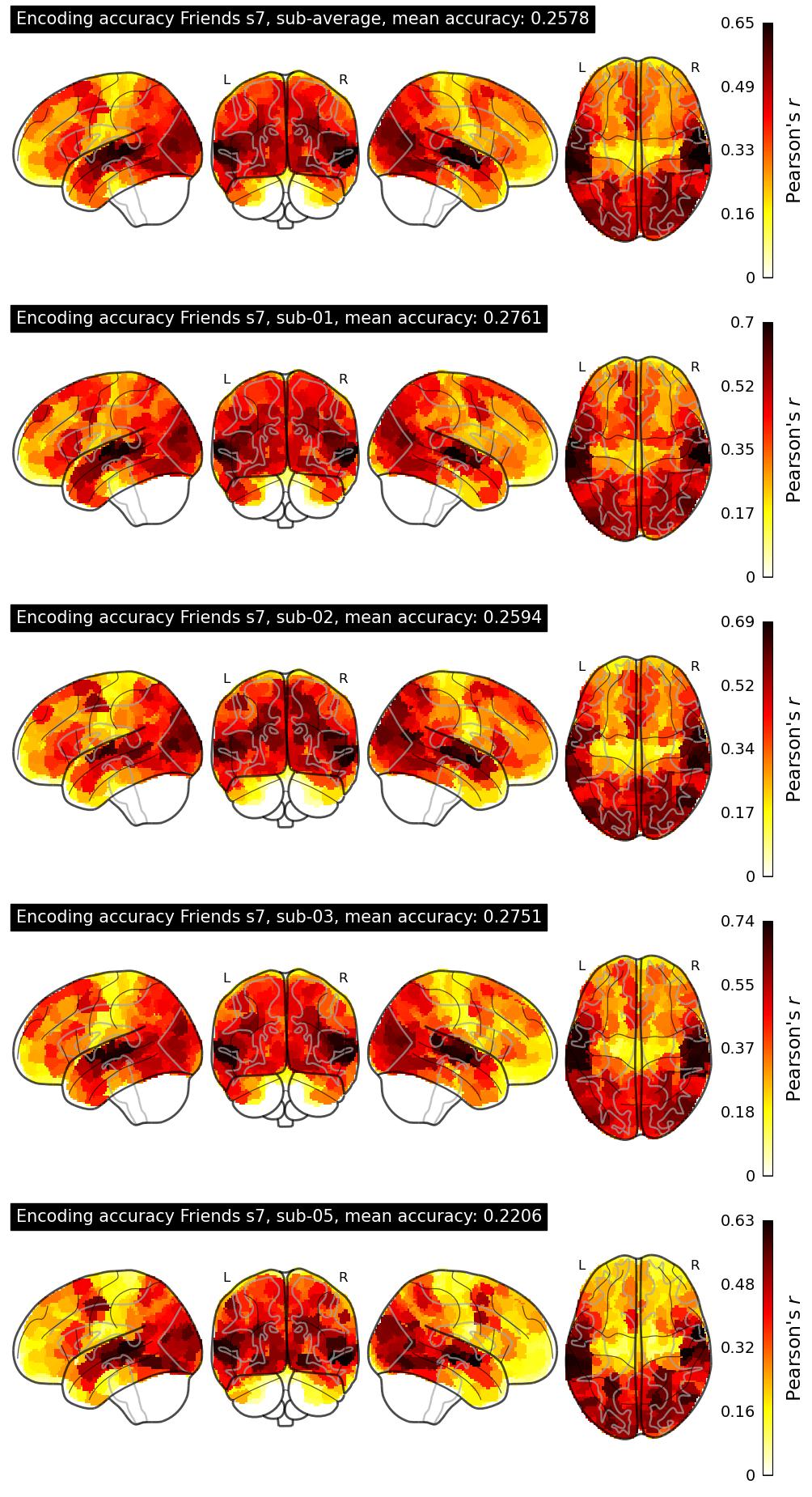
| 12 | cindyhfls | 0.2578 | Visualization | ||
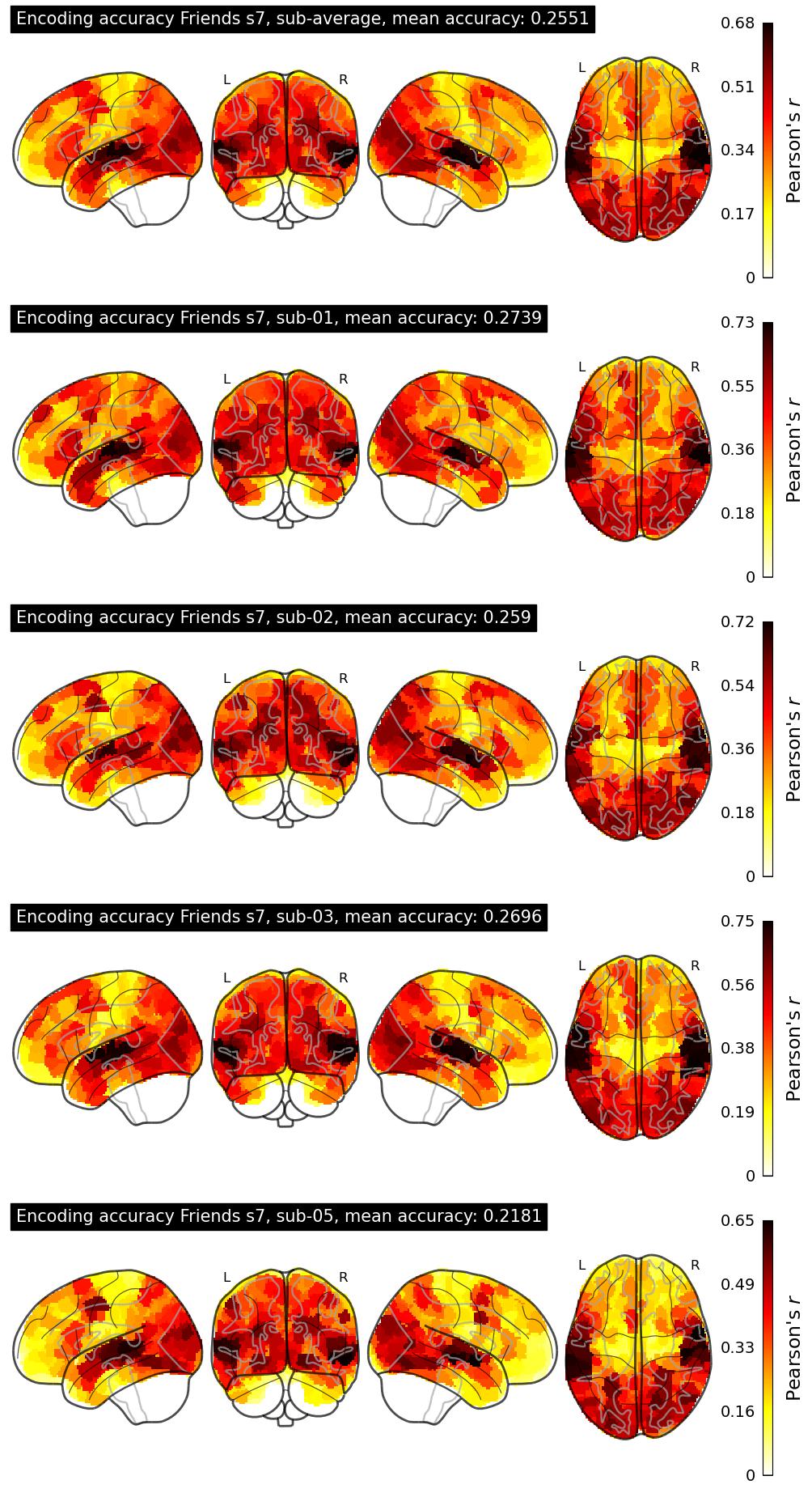
| 13 | aditisaxena | 0.2551 | Visualization | ||
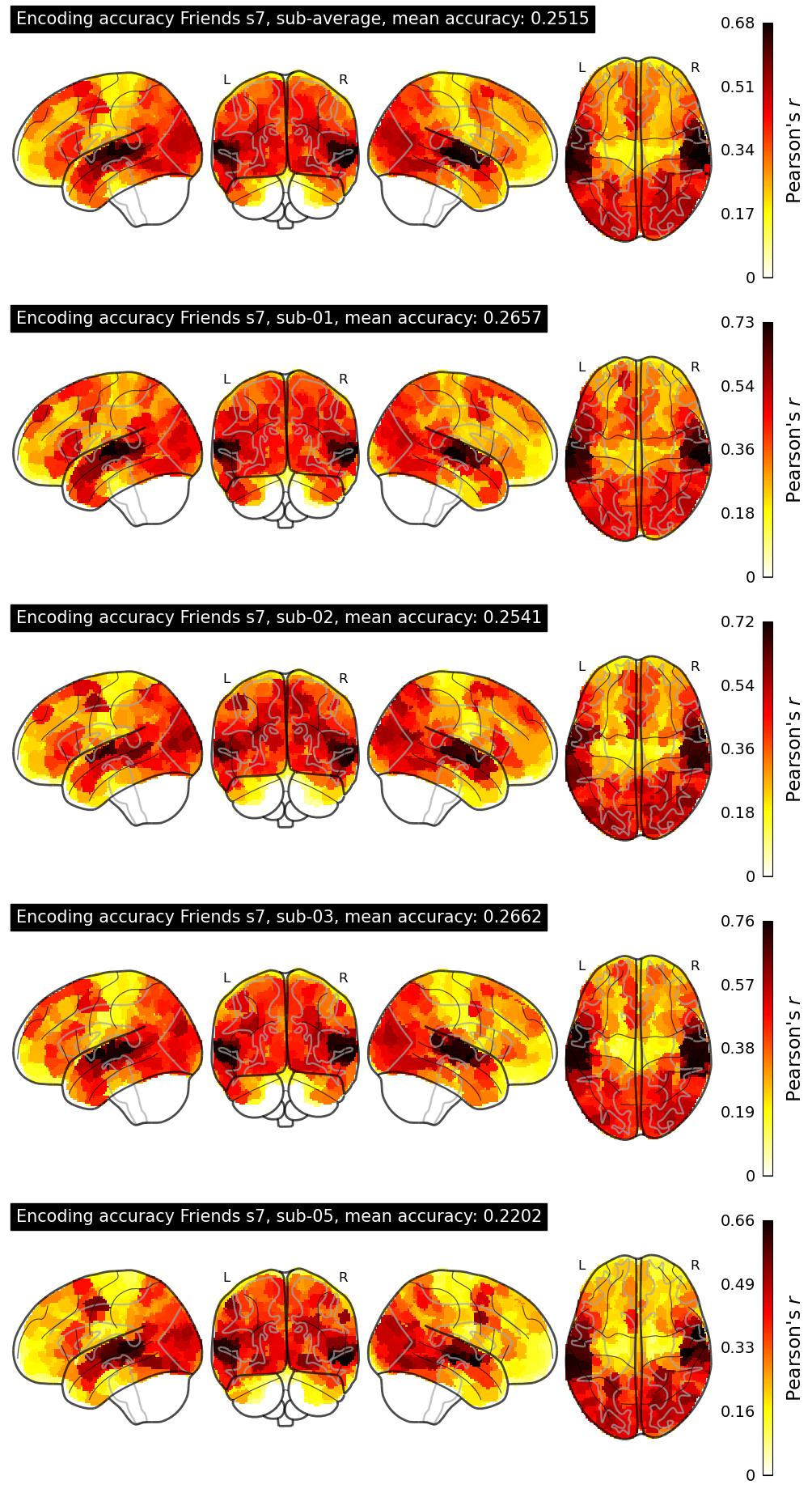
| 14 | jeremywei | 0.2515 | Visualization | ||
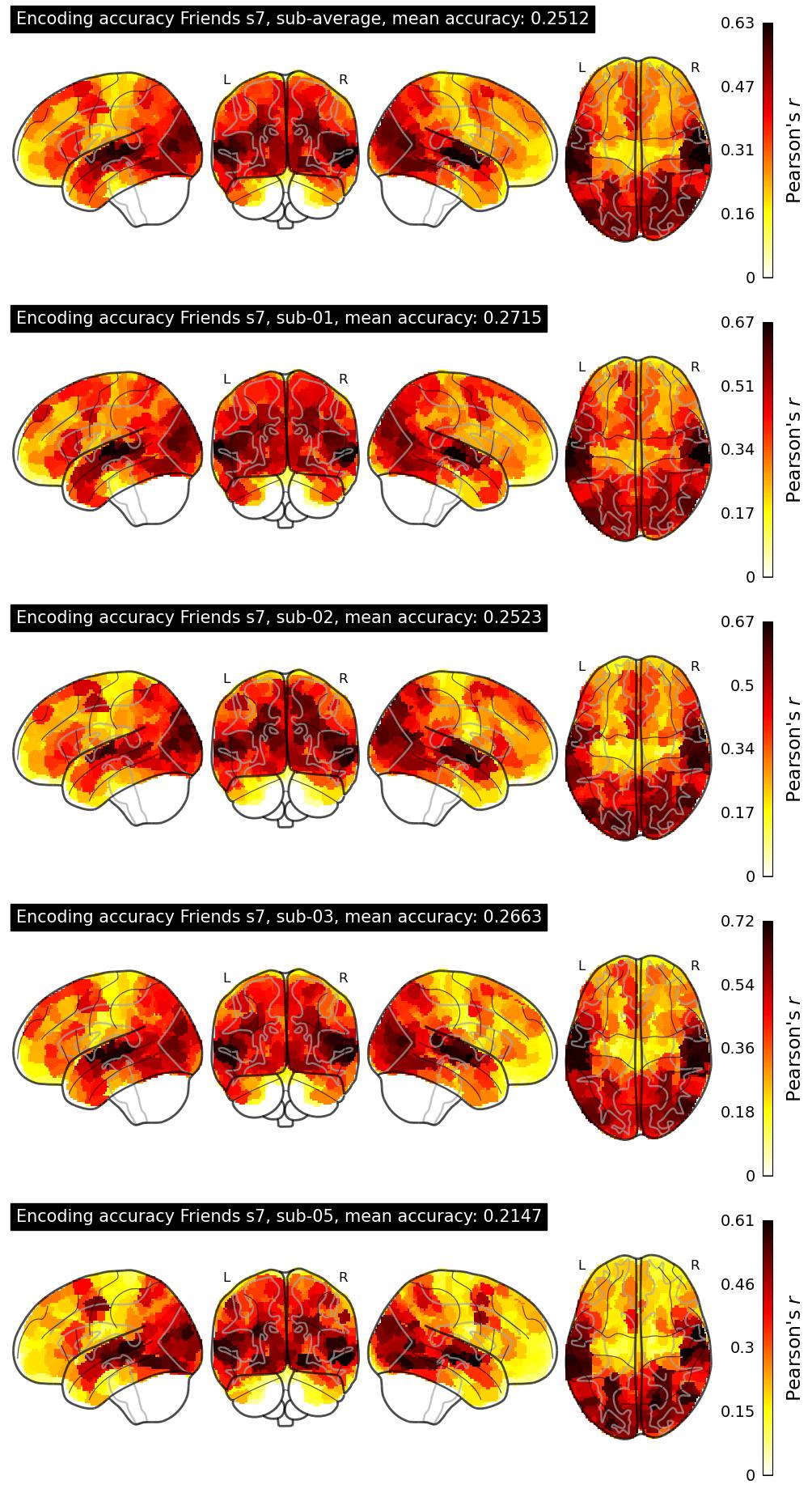
| 15 | mainak09 | 0.2512 | Visualization | ||
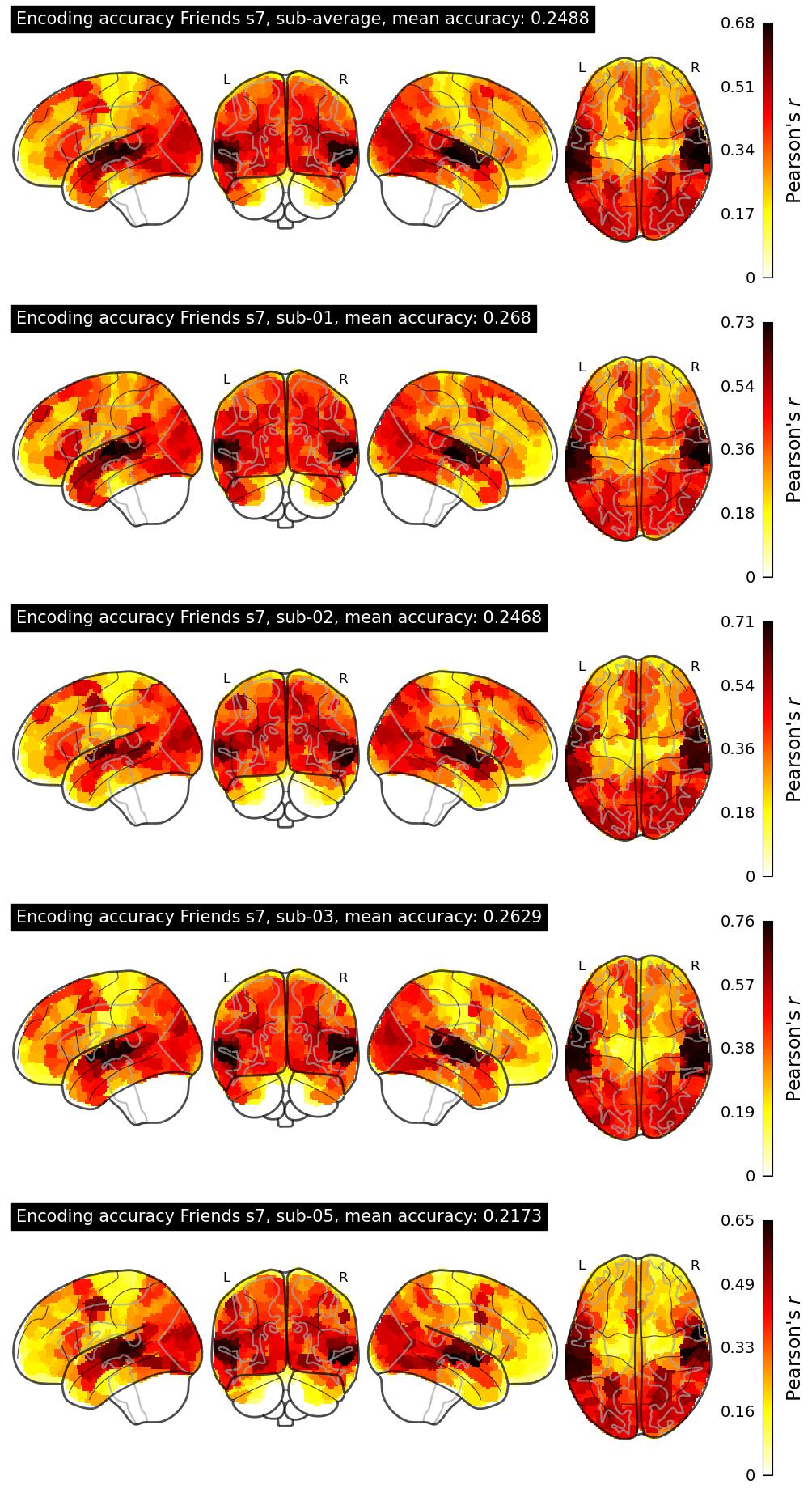
| 16 | gabe_persson | 0.2488 | Visualization | ||
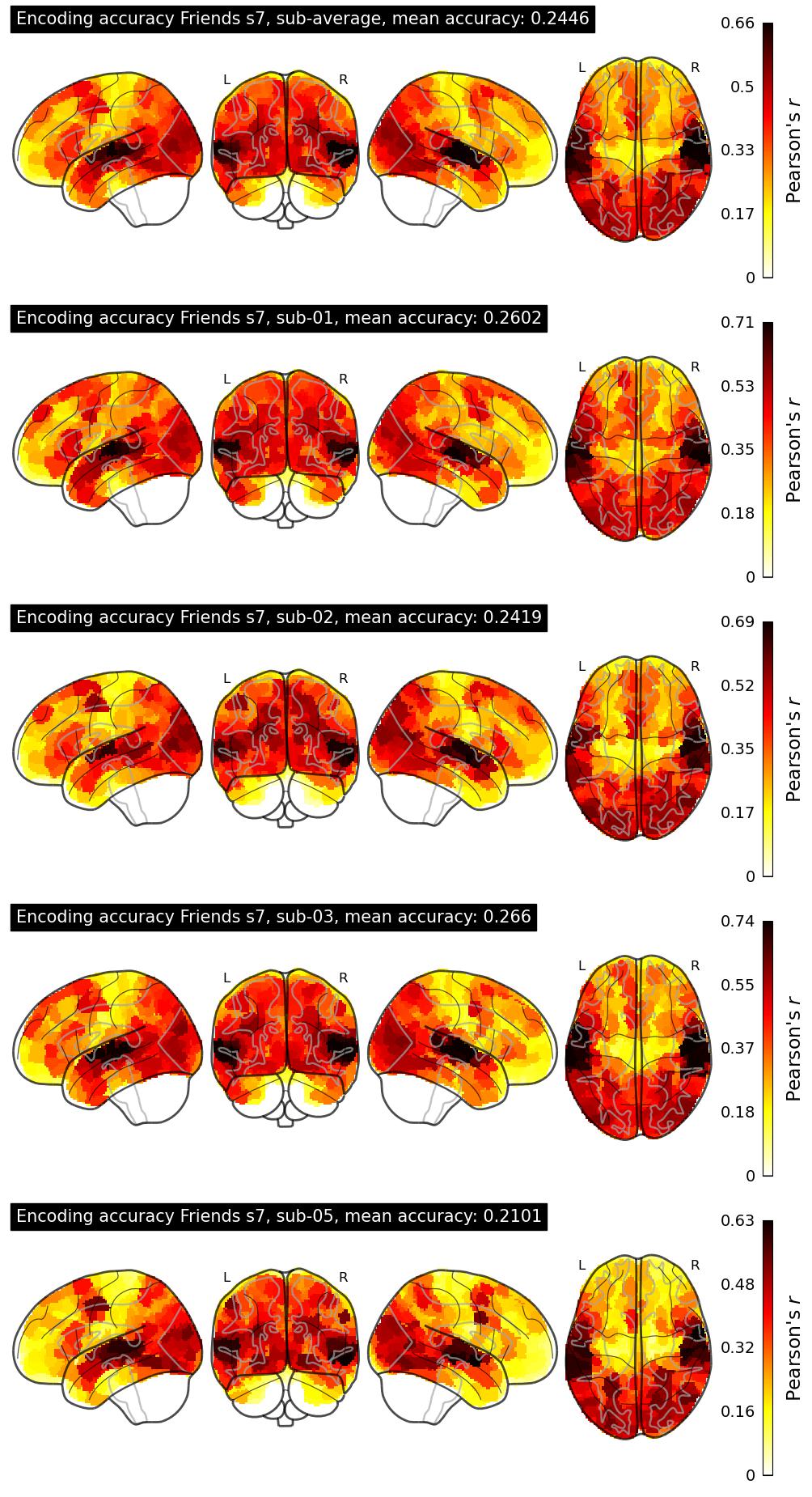
| 17 | ryota1 | 0.2446 | Visualization | ||
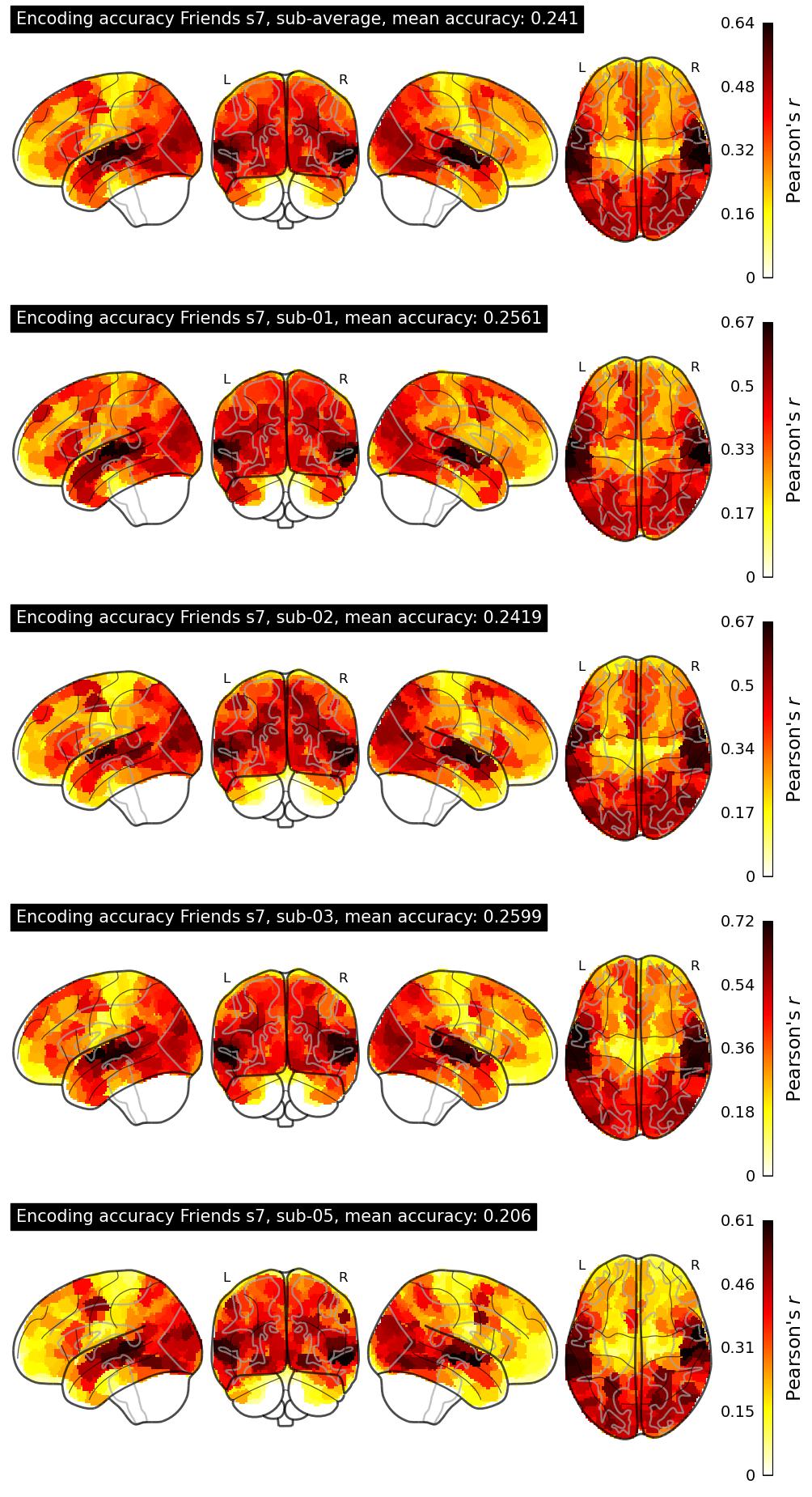
| 18 | pcnlab | 0.2410 | Visualization | ||
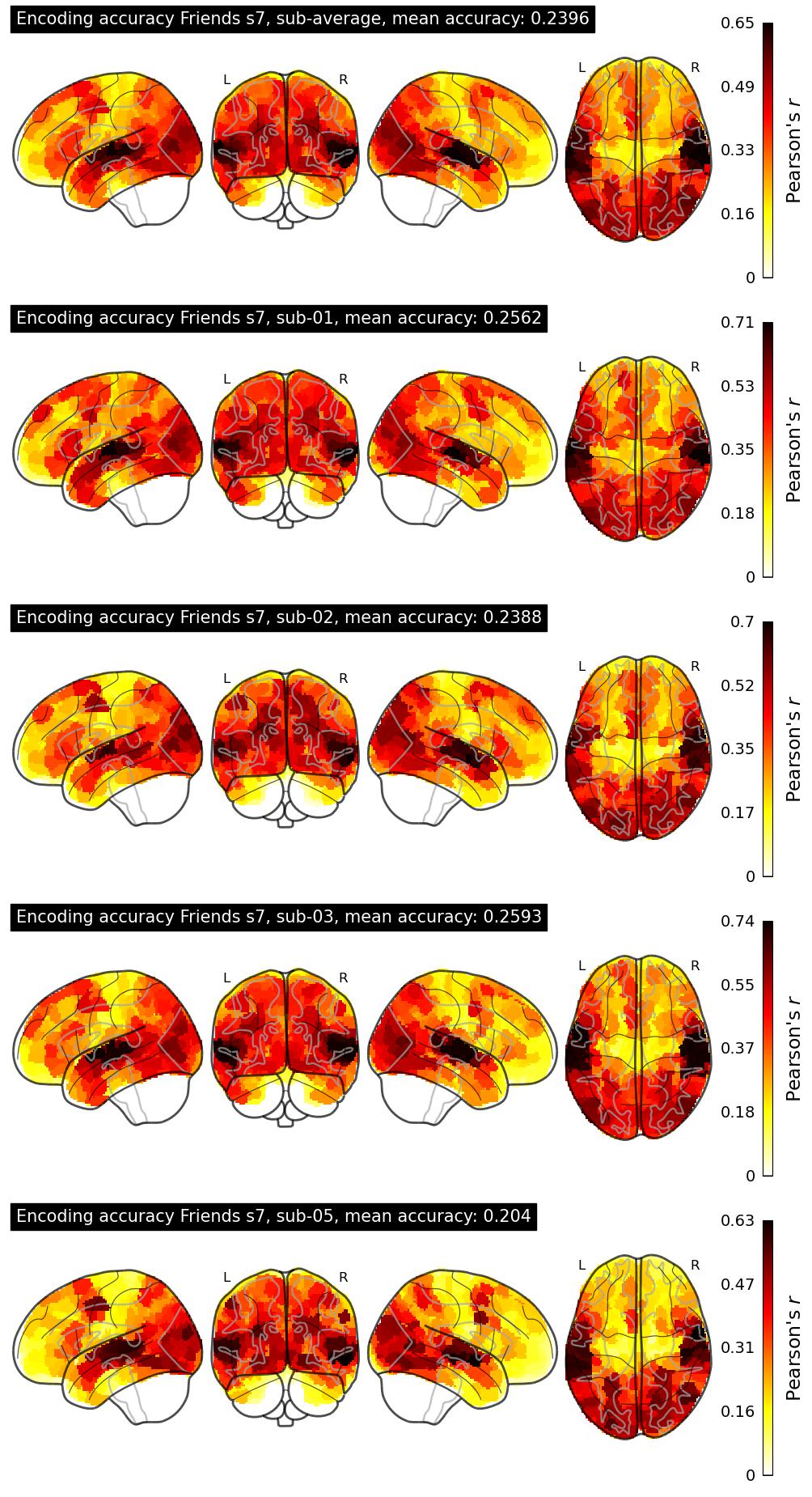
| 19 | liandan | 0.2396 | Visualization | ||
| 20 | goodyourbro | 0.2389 | Visualization | ||
| 21 | Kunal Bagga | 0.2378 | Visualization | ||
| 22 | viacheus | 0.2272 | Visualization | ||
| 23 | robertscholz | 0.2272 | Visualization | ||
| 24 | hara | 0.2230 | Visualization | ||
| 25 | SJC | 0.2229 | Visualization | ||
| 26 | sabertoaster | 0.2218 | Visualization | ||
| 27 | arielbundy | 0.2184 | Visualization | ||
| 28 | DIO Research Lab - AUT | 0.2180 | Visualization | ||
| 29 | msgastli | 0.2111 | Visualization | ||
| 30 | hgz20 | 0.2058 | Visualization | ||
| 31 | shuxiao | 0.2057 | Visualization | ||
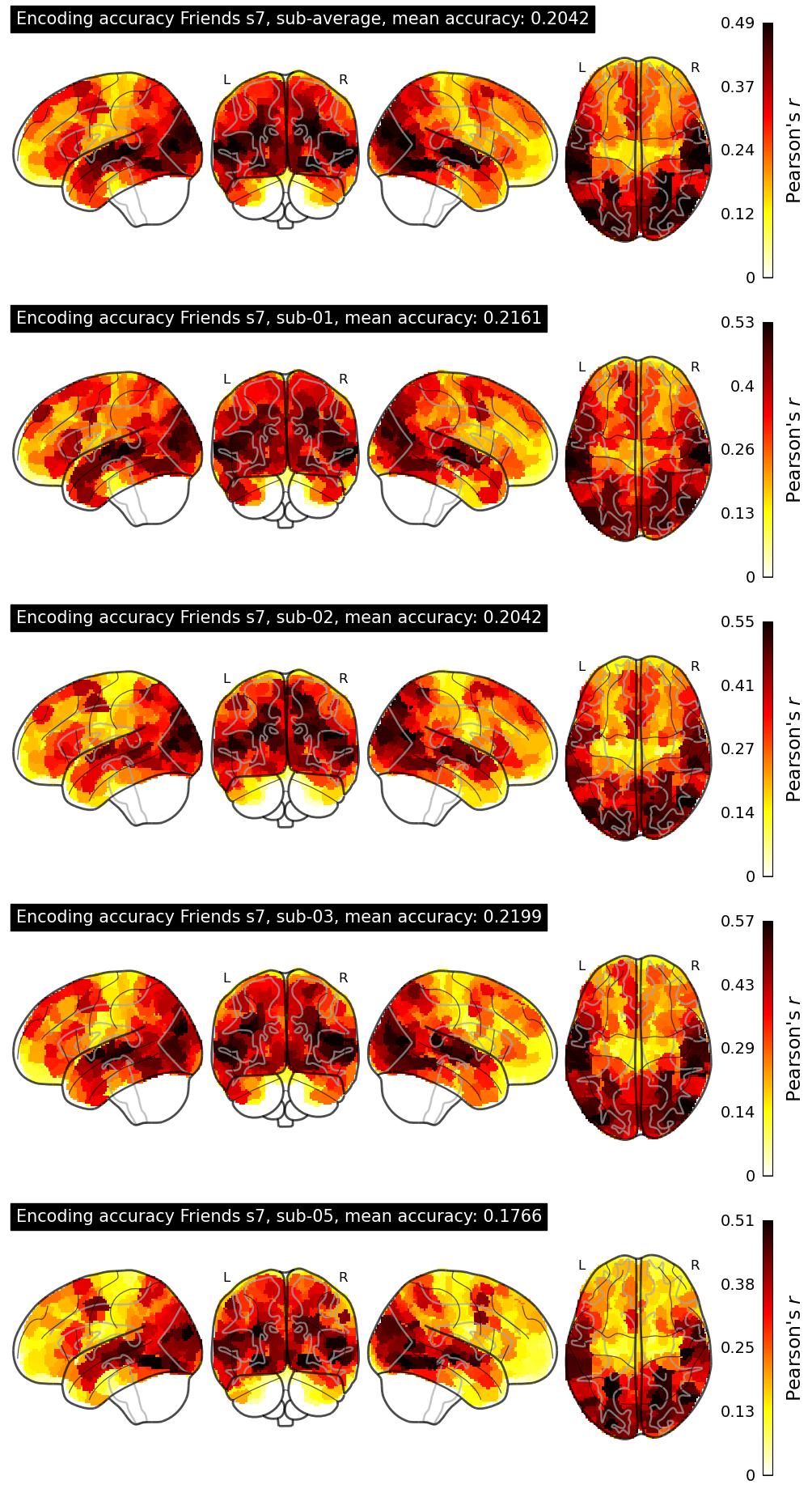
| 32 | Nap | 0.2042 | Visualization | ||
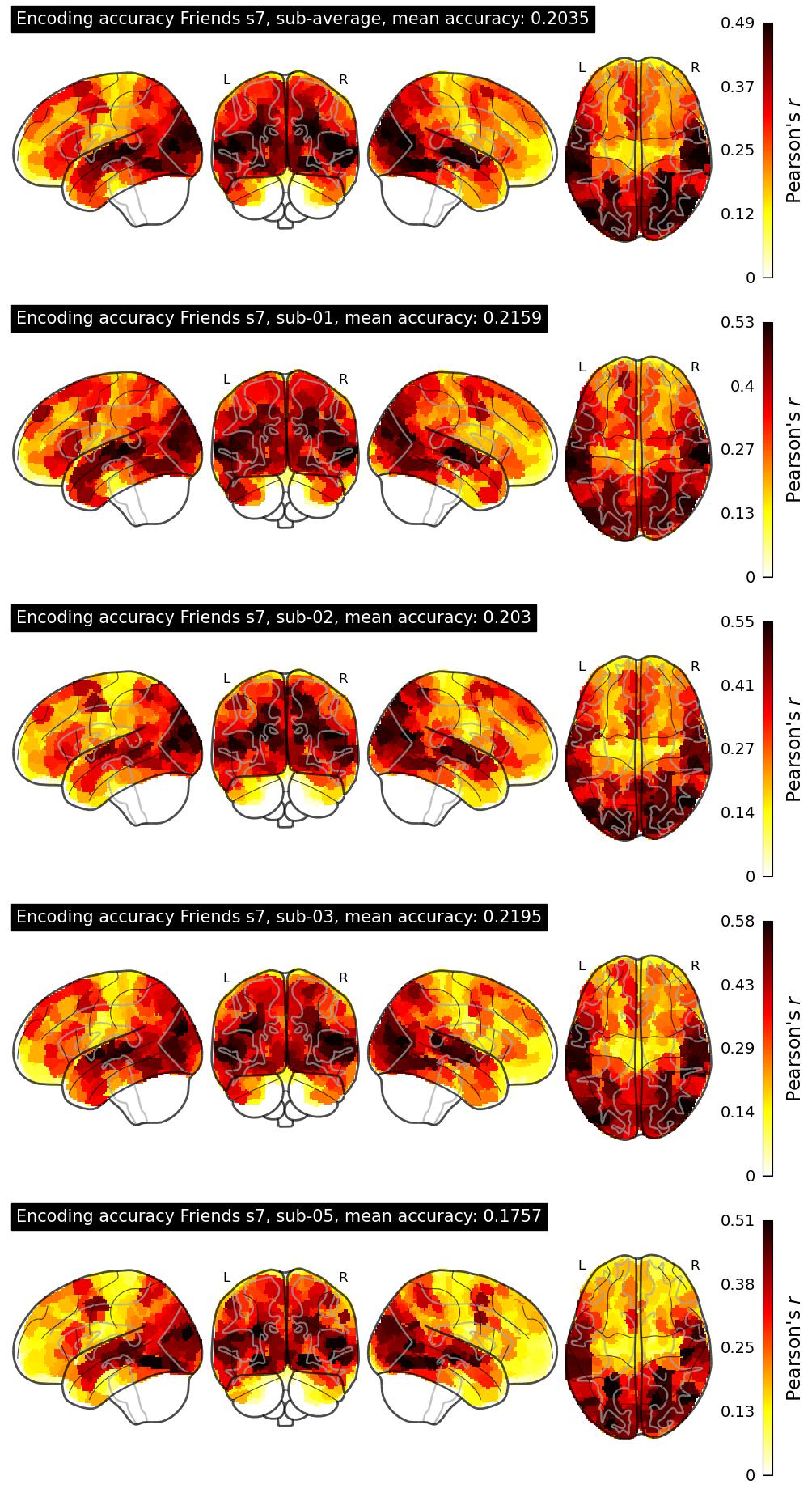
| 33 | kyky | 0.2035 | Visualization | ||
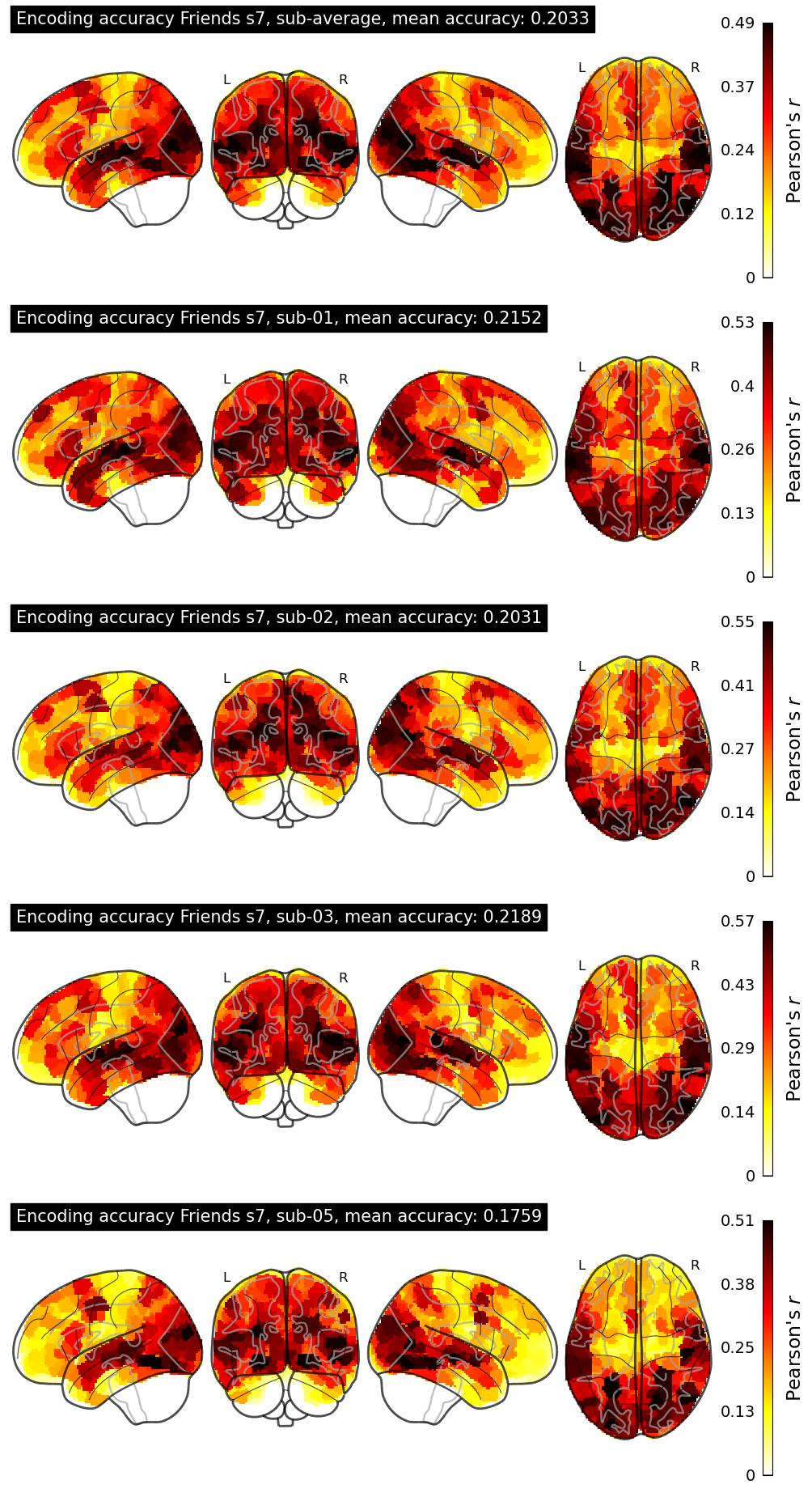
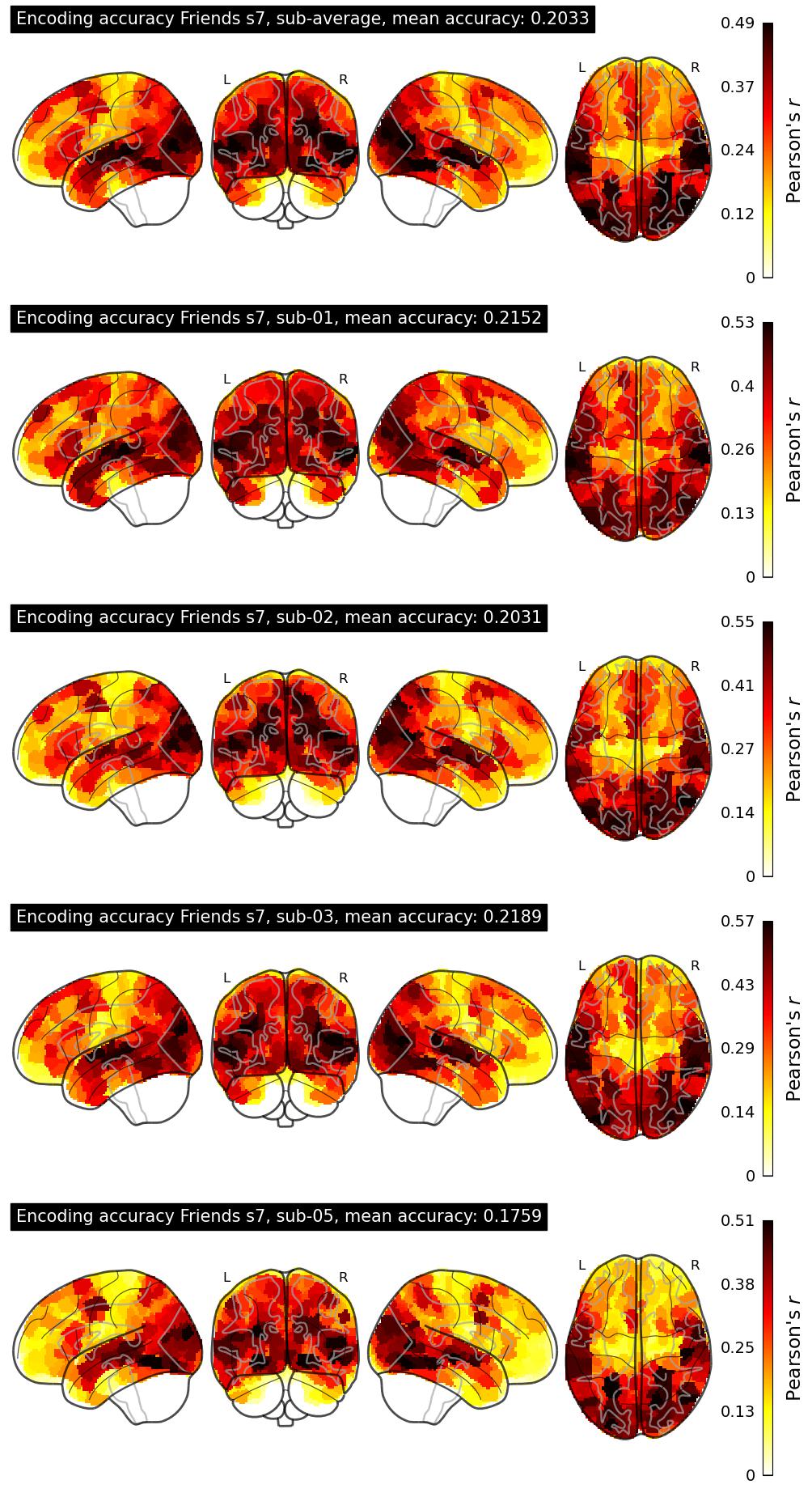
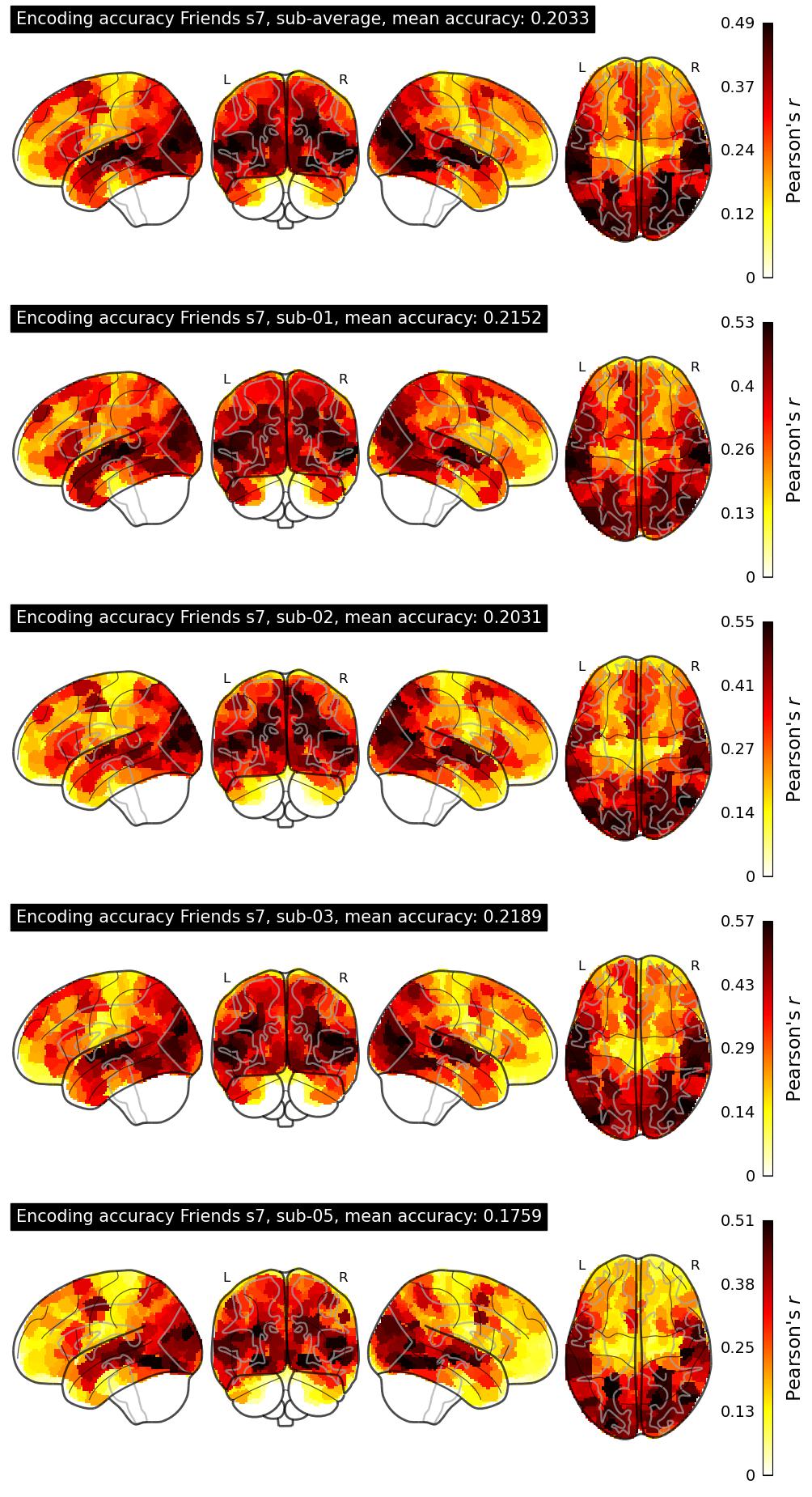
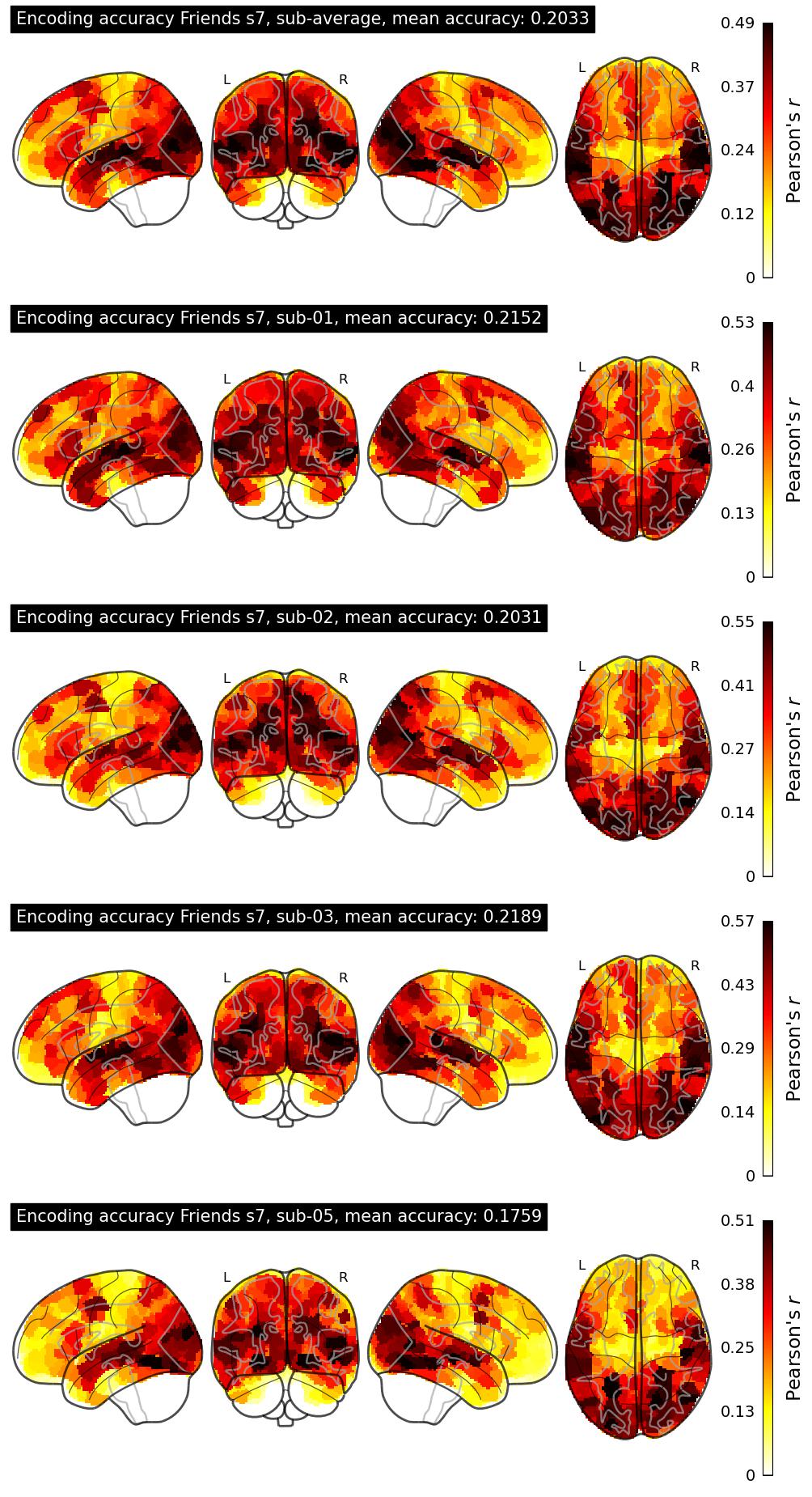
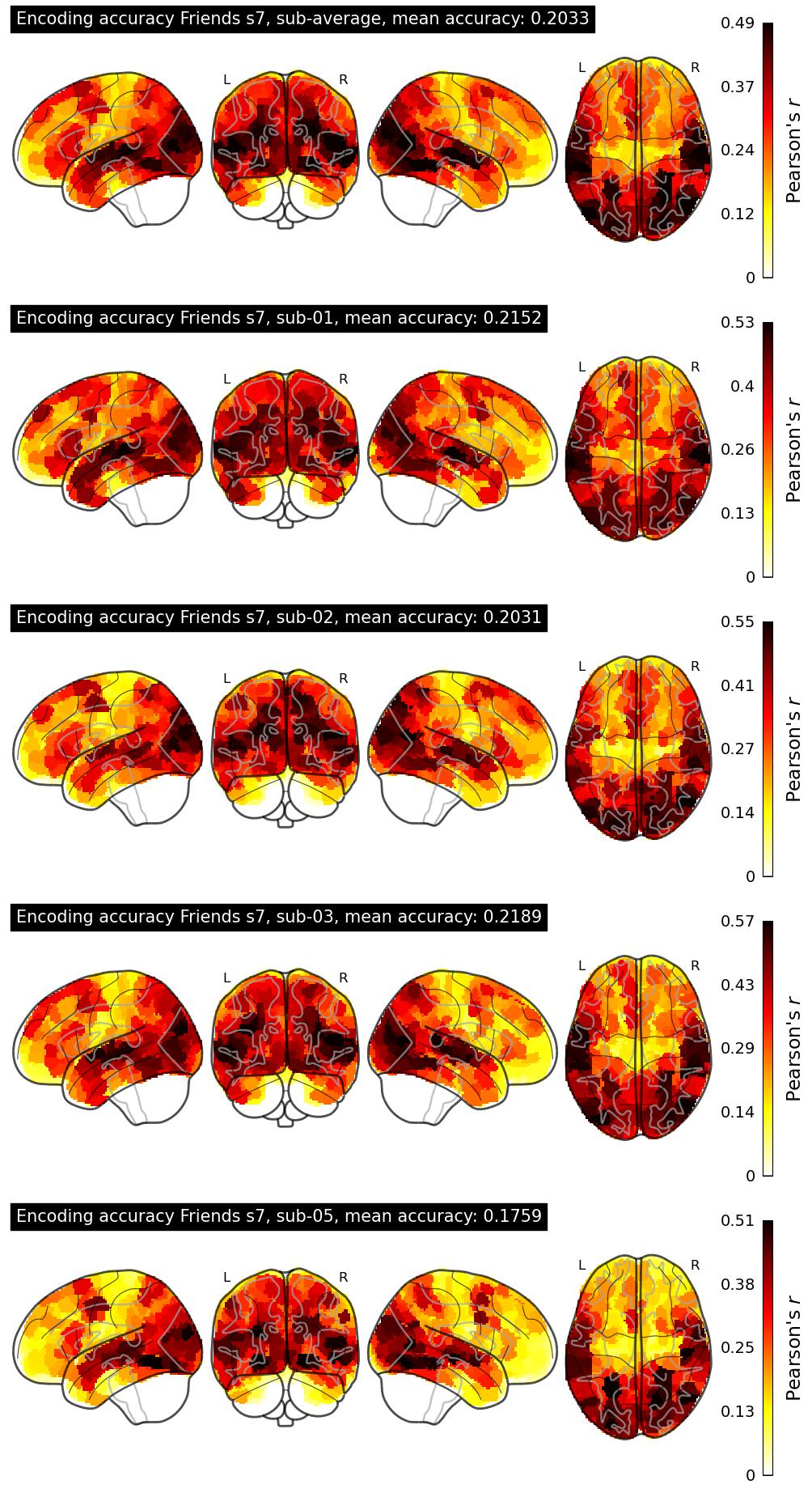
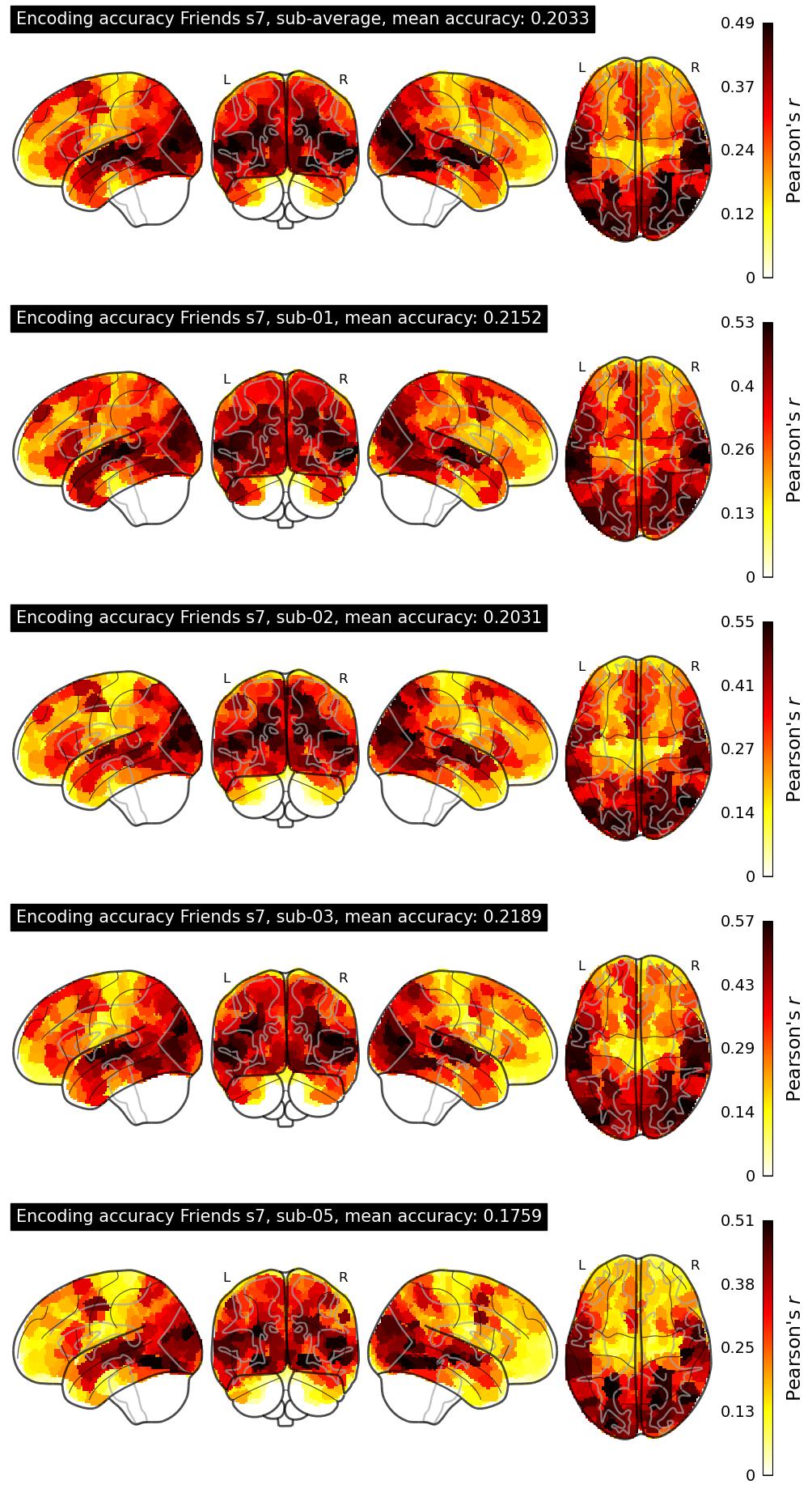
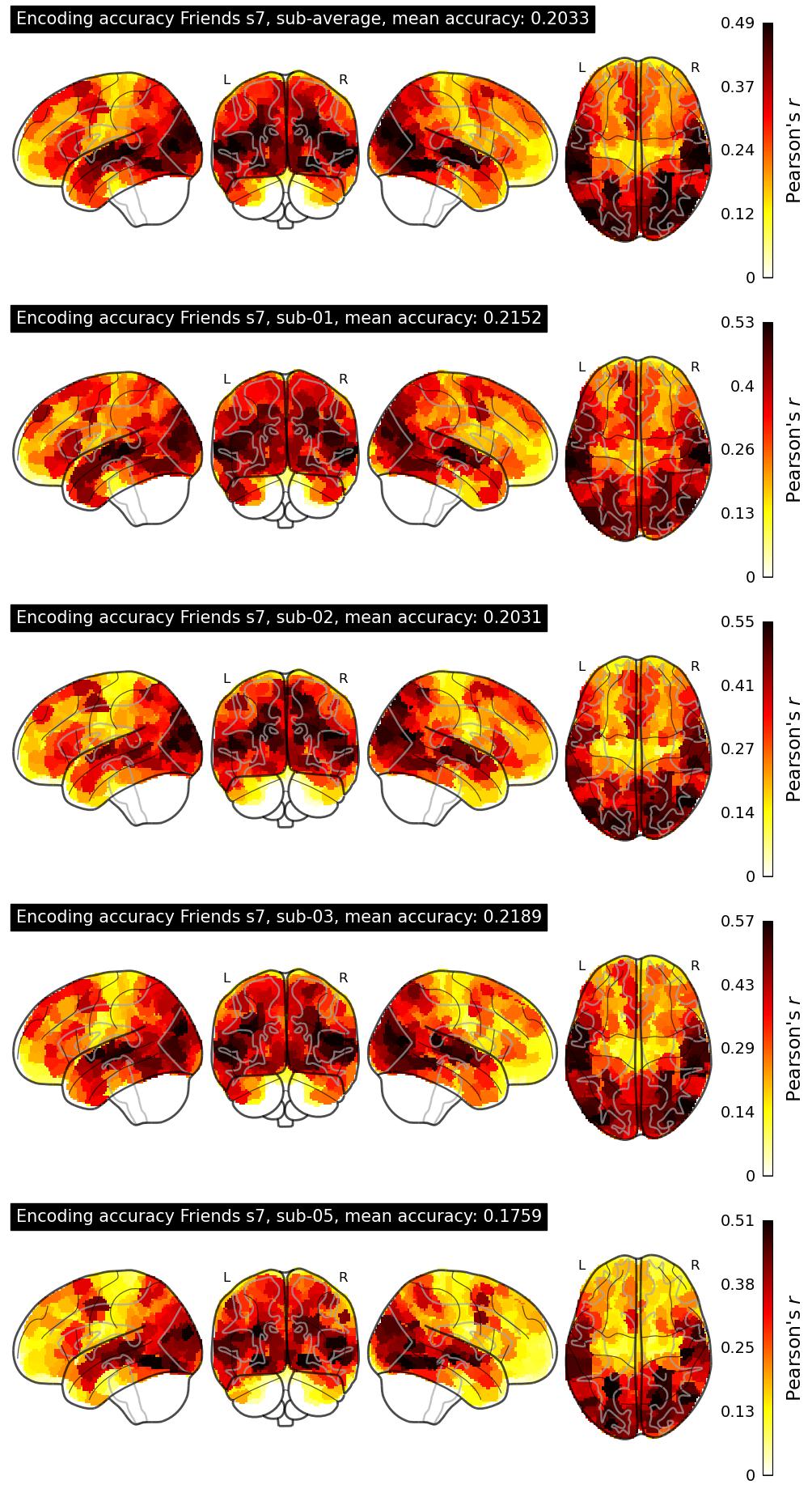
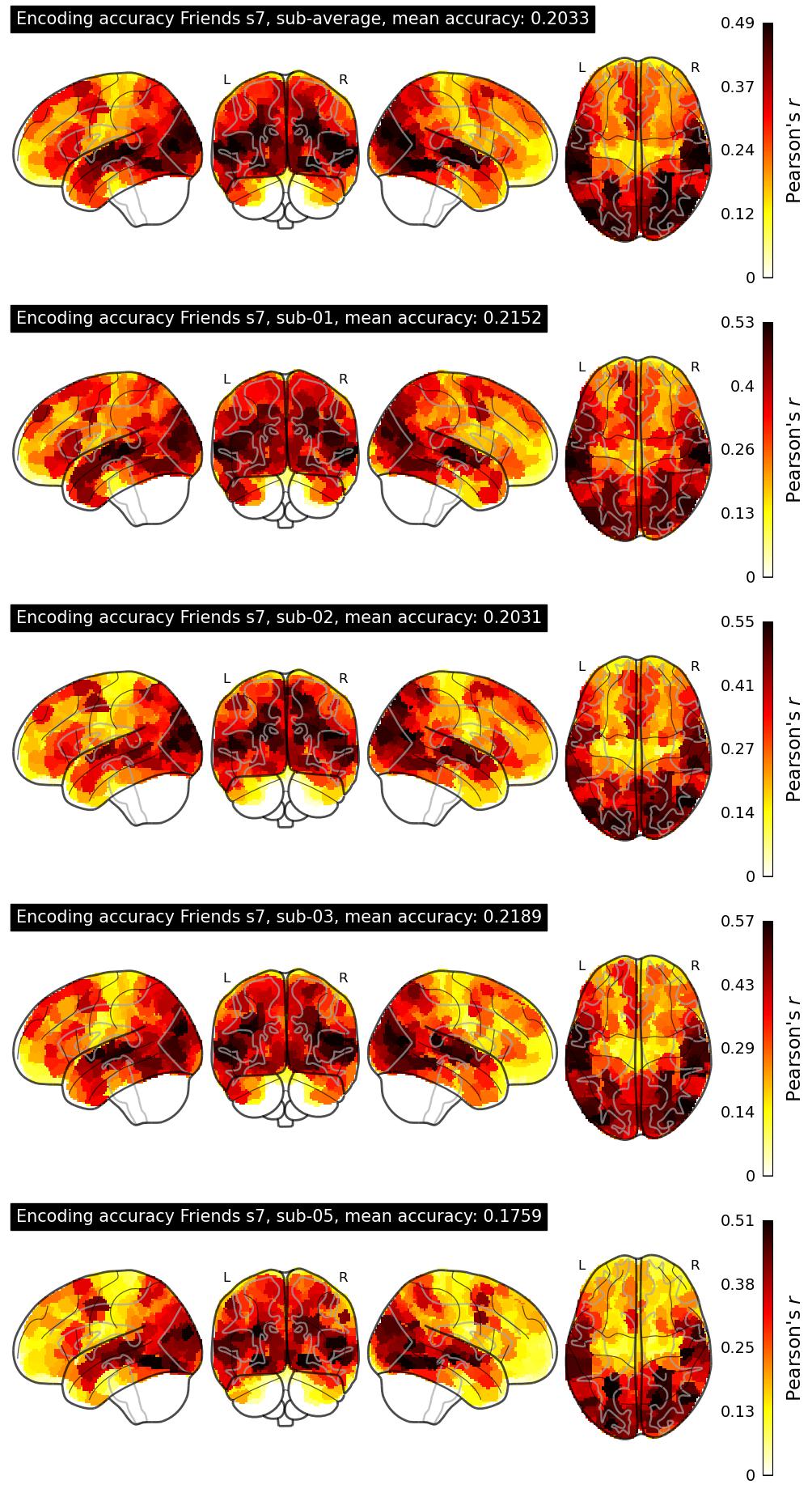
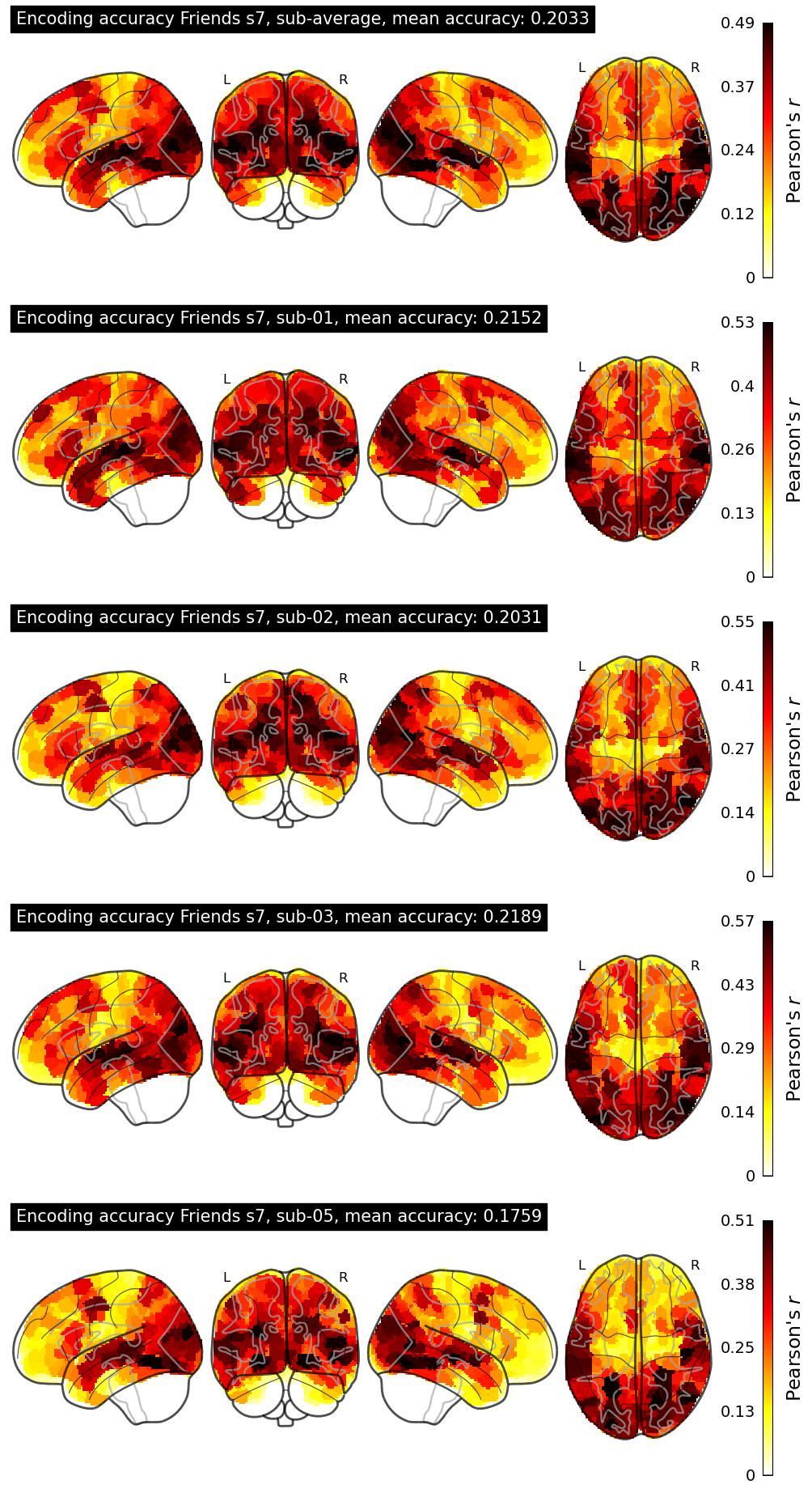
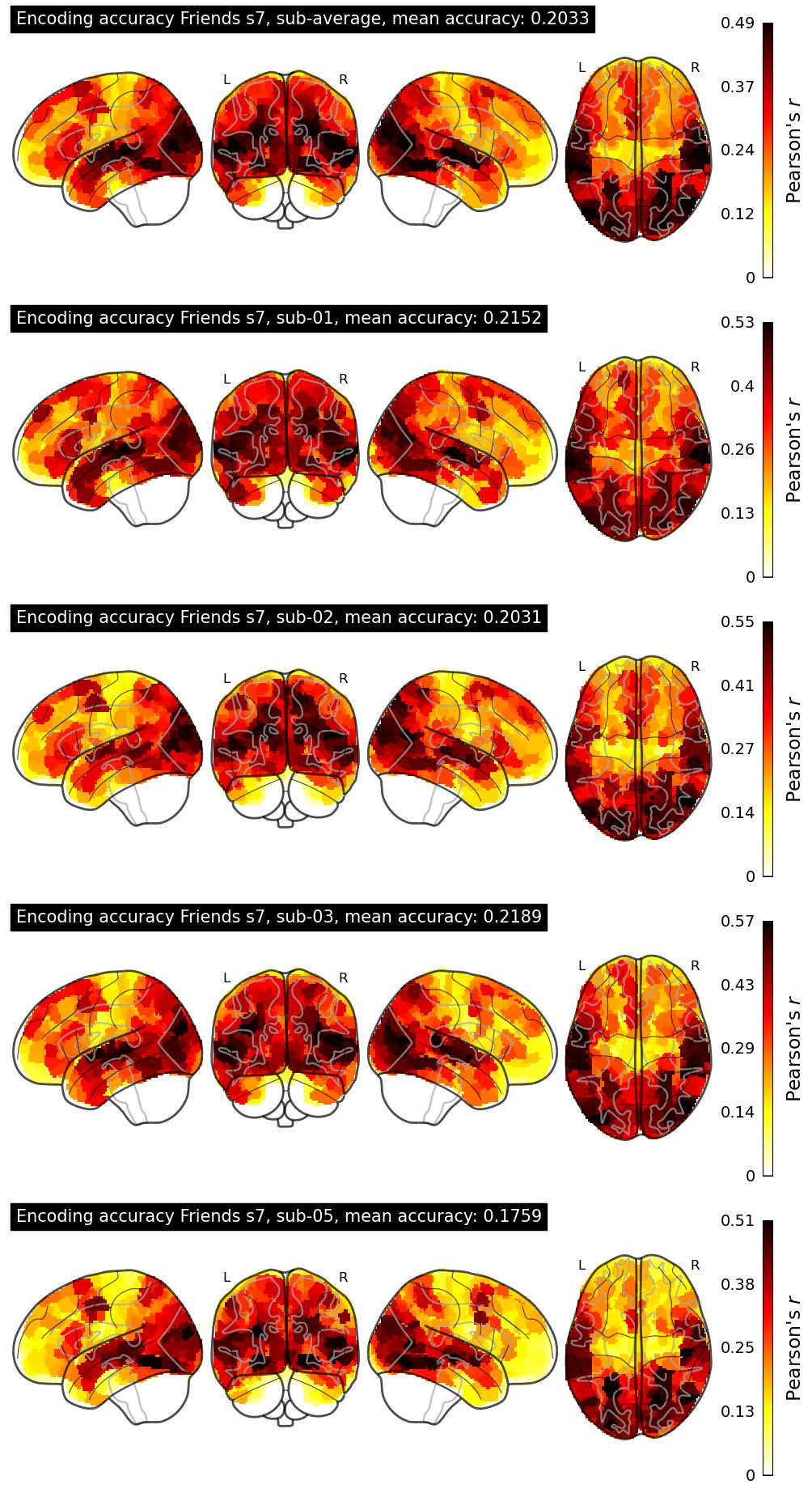
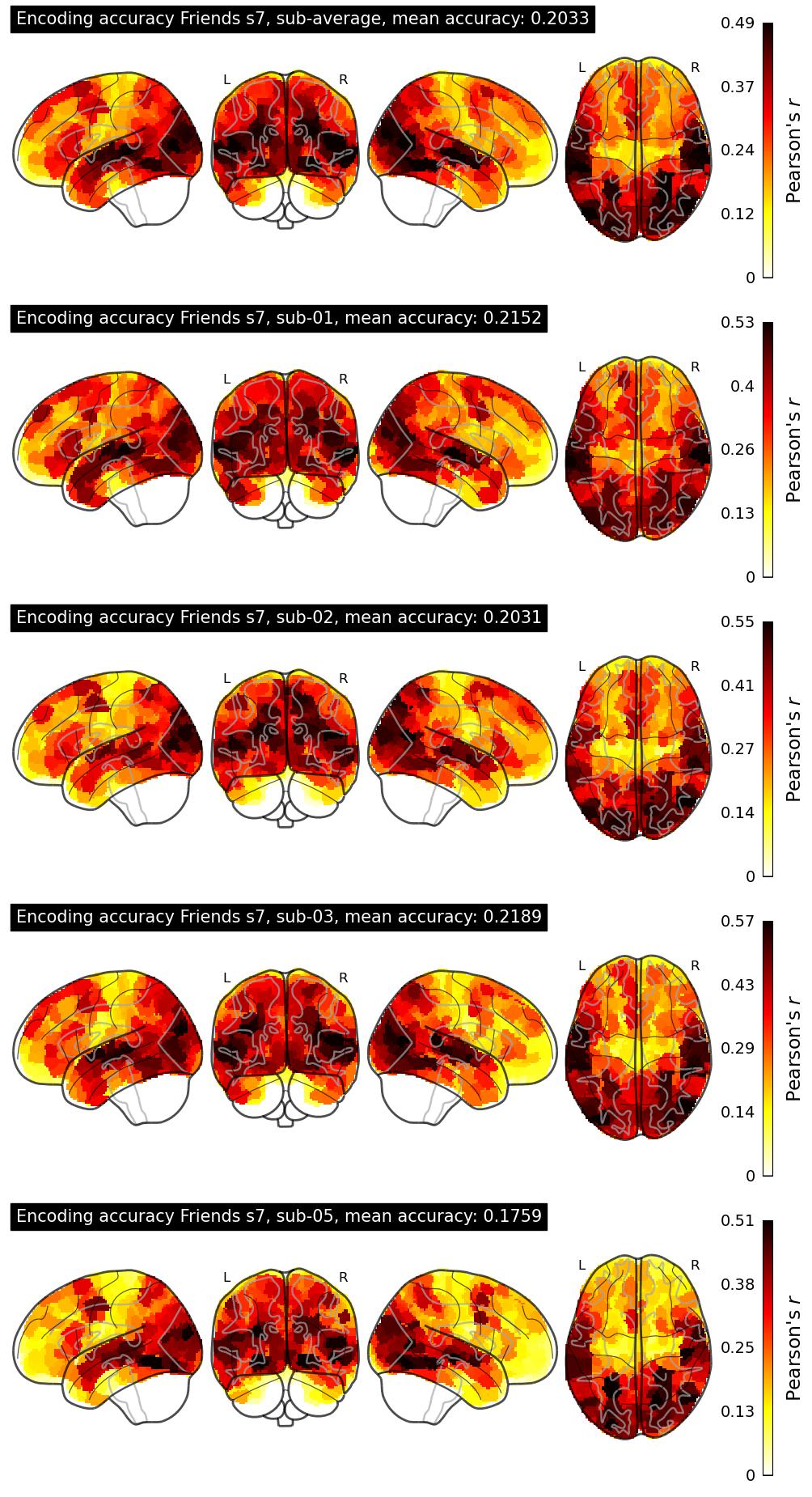
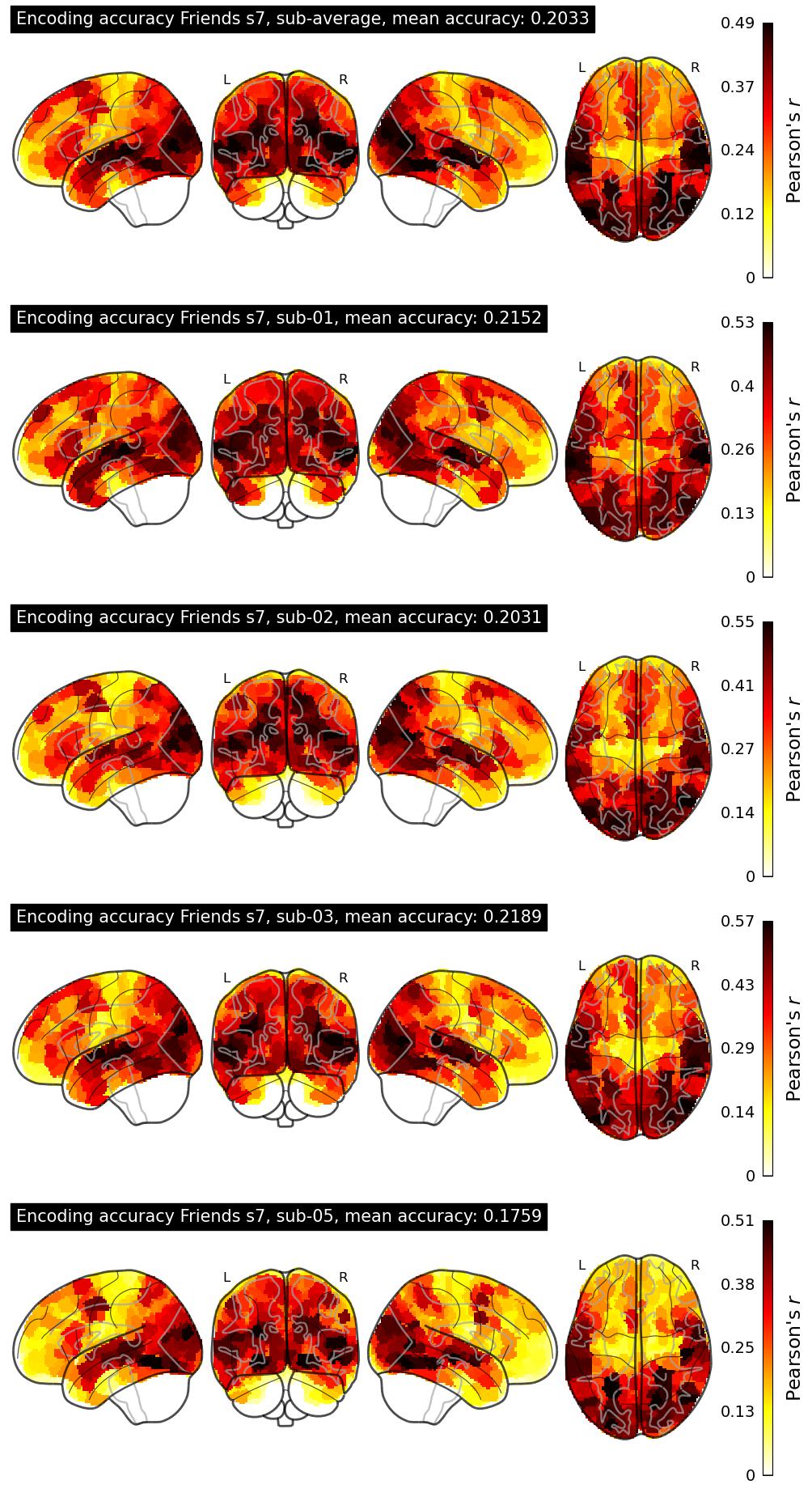
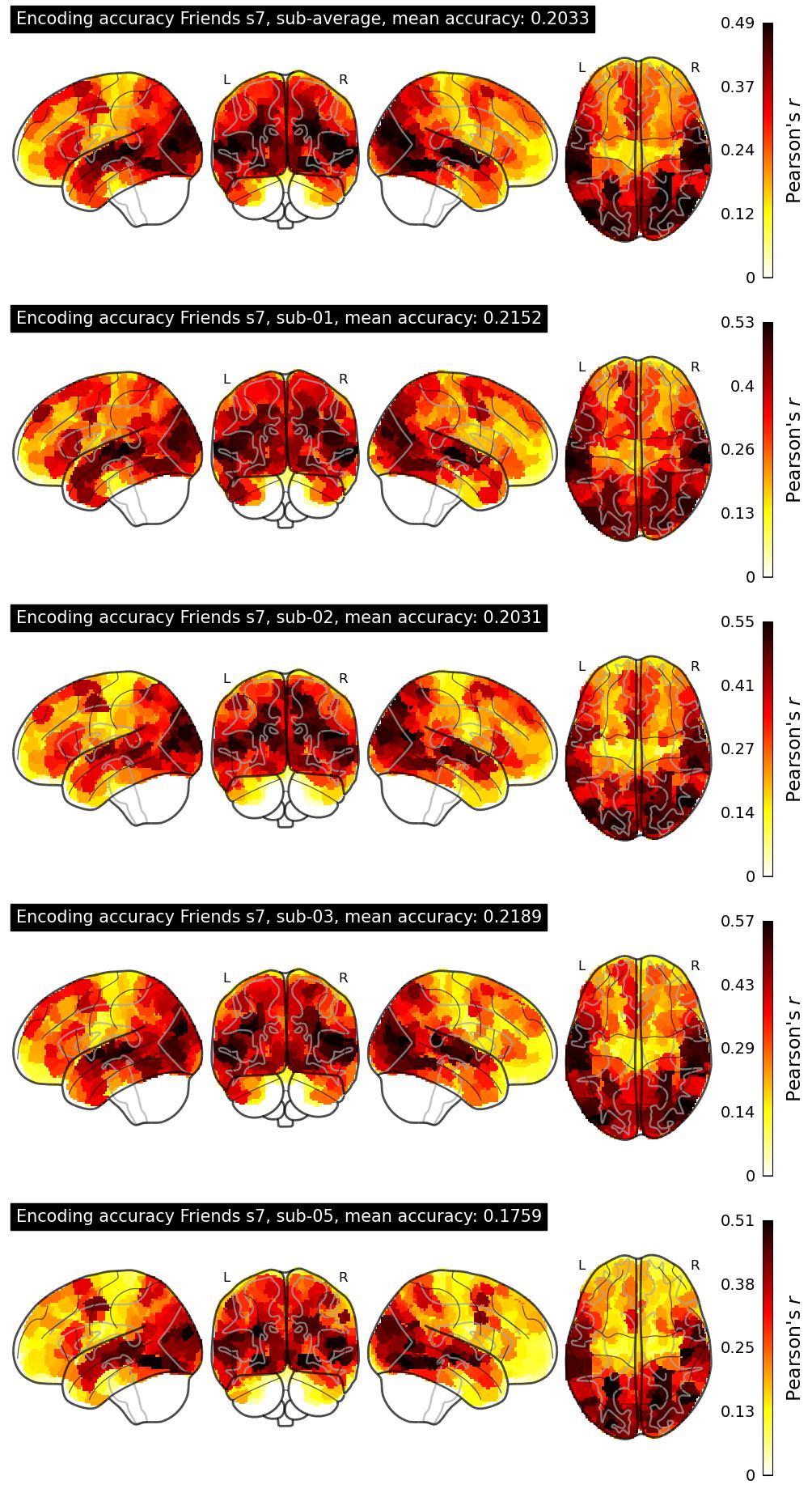
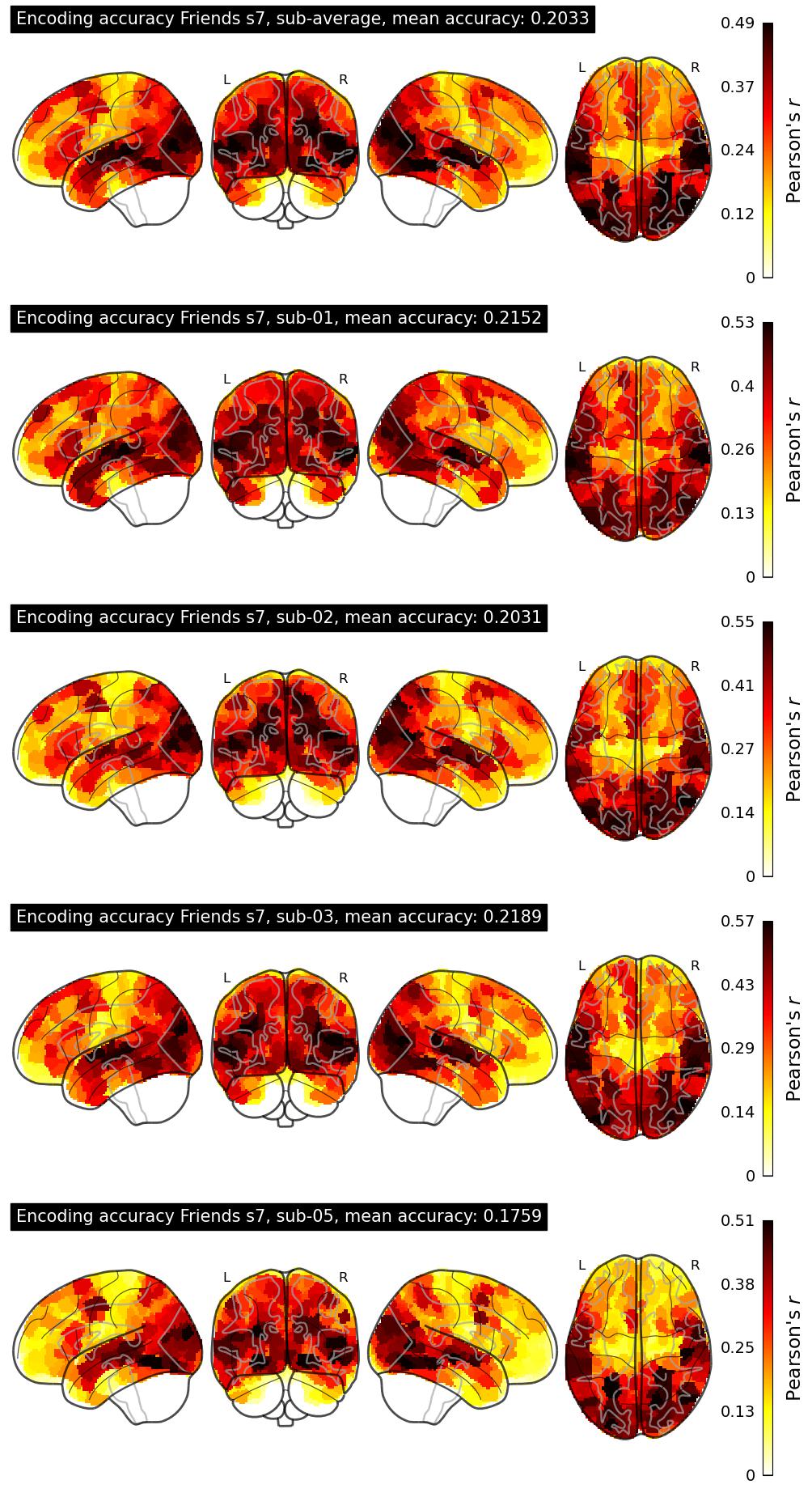
| 34 | baseline | 0.2033 | Visualization | ||
| 35 | deleted_user_14577 | 0.2033 | Visualization | ||
| 36 | Karim ROCHD | 0.2033 | Visualization | ||
| 37 | siler | 0.2033 | Visualization | ||
| 38 | adrianrefe4 | 0.2033 | Visualization | ||
| 39 | genandlam | 0.2033 | Visualization | ||
| 40 | guard-mann | 0.2033 | Visualization | ||
| 41 | killz | 0.2033 | Visualization | ||
| 42 | nekopara | 0.2033 | Visualization | ||
| 43 | shem004 | 0.2033 | Visualization | ||
| 44 | richardkk | 0.2033 | Visualization | ||
| 45 | harshvardhan | 0.2033 | Visualization | ||
| 46 | 20alicial | 0.2033 | Visualization | ||
| 47 | jonathan2329 | 0.2033 | Visualization | ||
| 48 | hippocampusgirl | 0.2033 | Visualization | ||
| 49 | mihirneal | 0.2033 | Visualization | ||
| 50 | tinganli | 0.1993 | Visualization | ||
| 51 | sivan | 0.1987 | Visualization | ||
| 52 | zhangxiaolong | 0.1962 | Visualization | ||
| 53 | testaccount2 | 0.1955 | Visualization | ||
| 54 | jessieccc | 0.1932 | Visualization | ||
| 55 | joelsp19 | 0.1929 | Visualization | ||
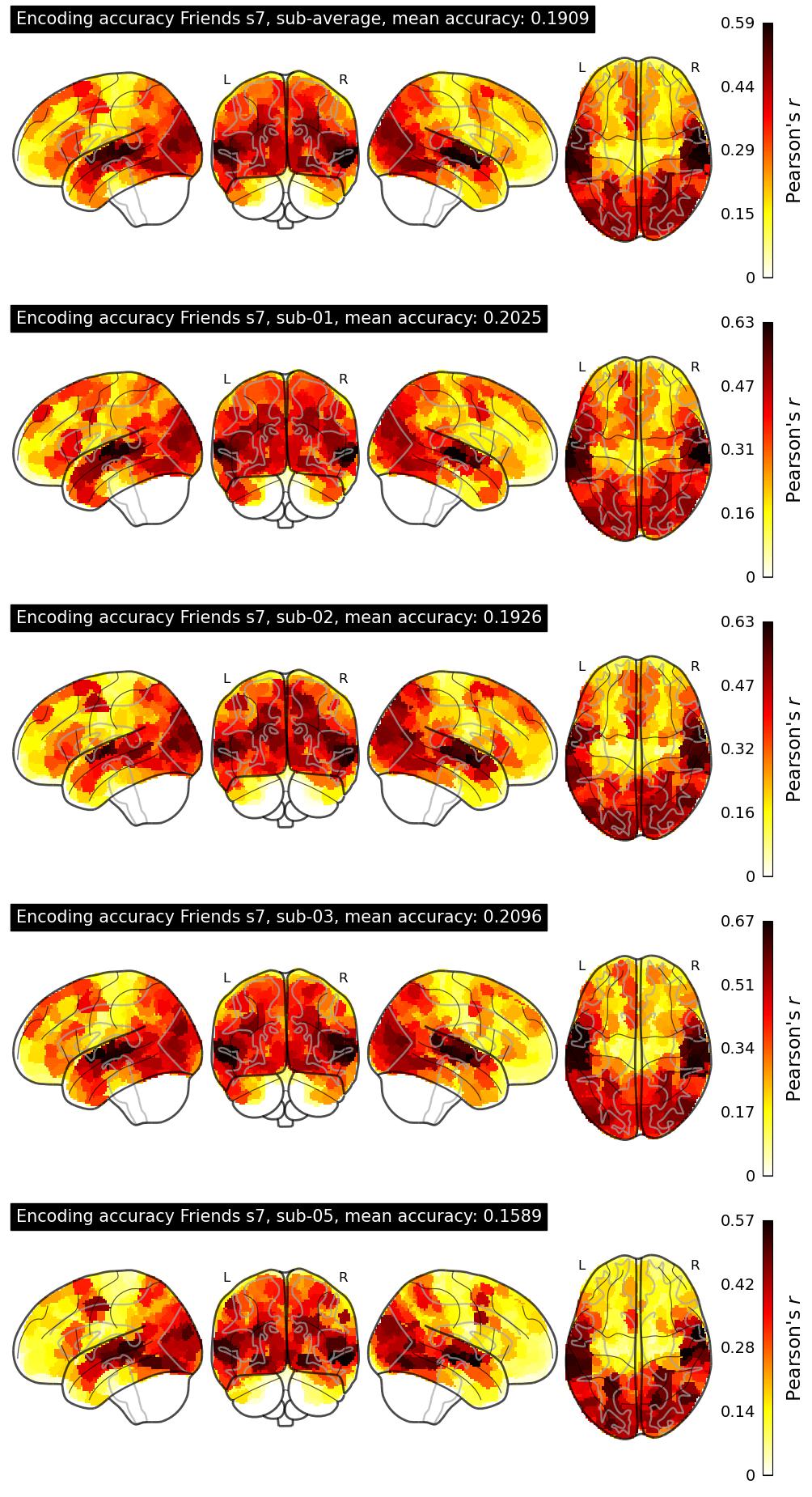
| 56 | lio | 0.1909 | Visualization | ||
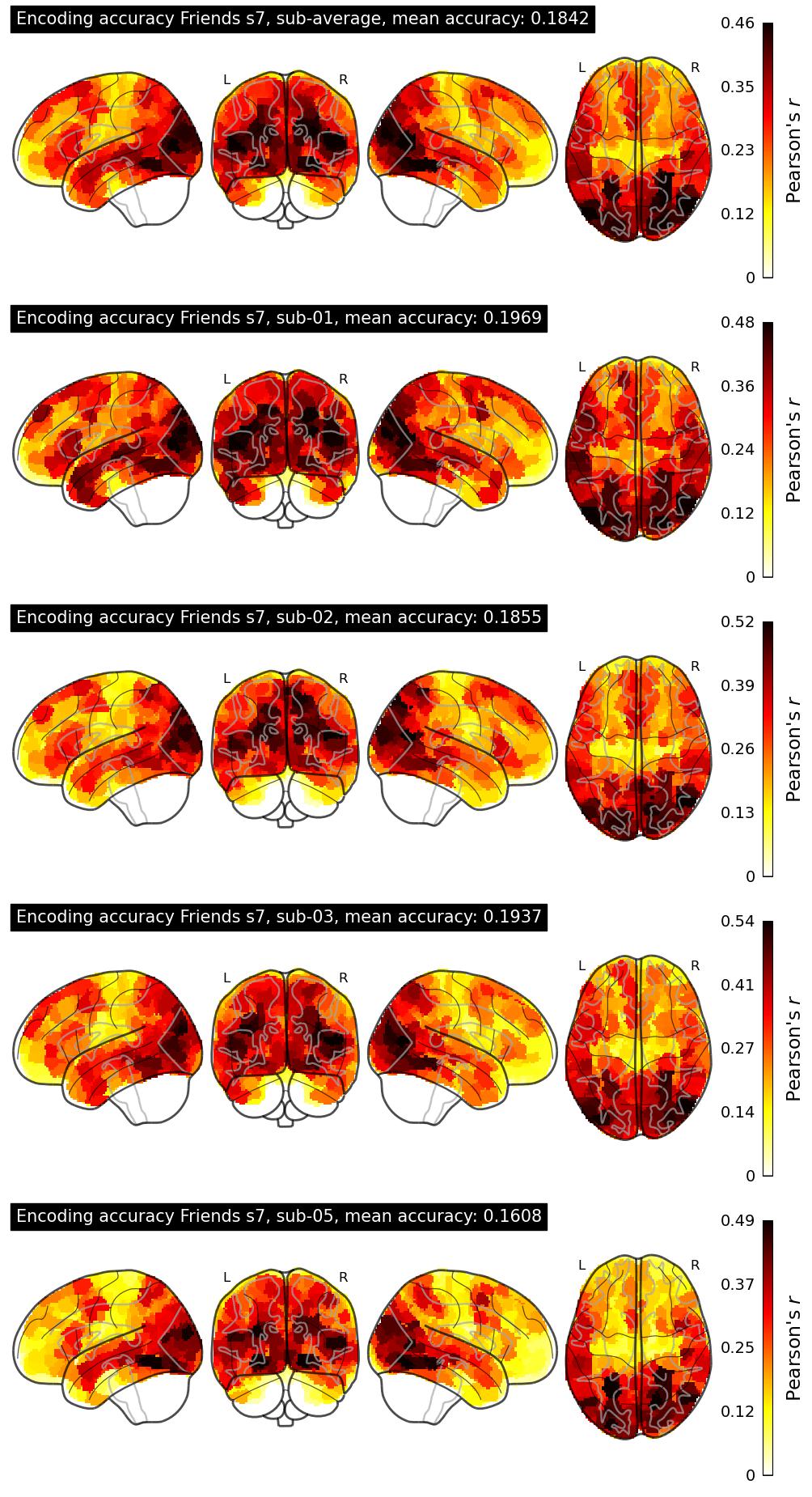
| 57 | victor_c_nardi | 0.1842 | Visualization | ||
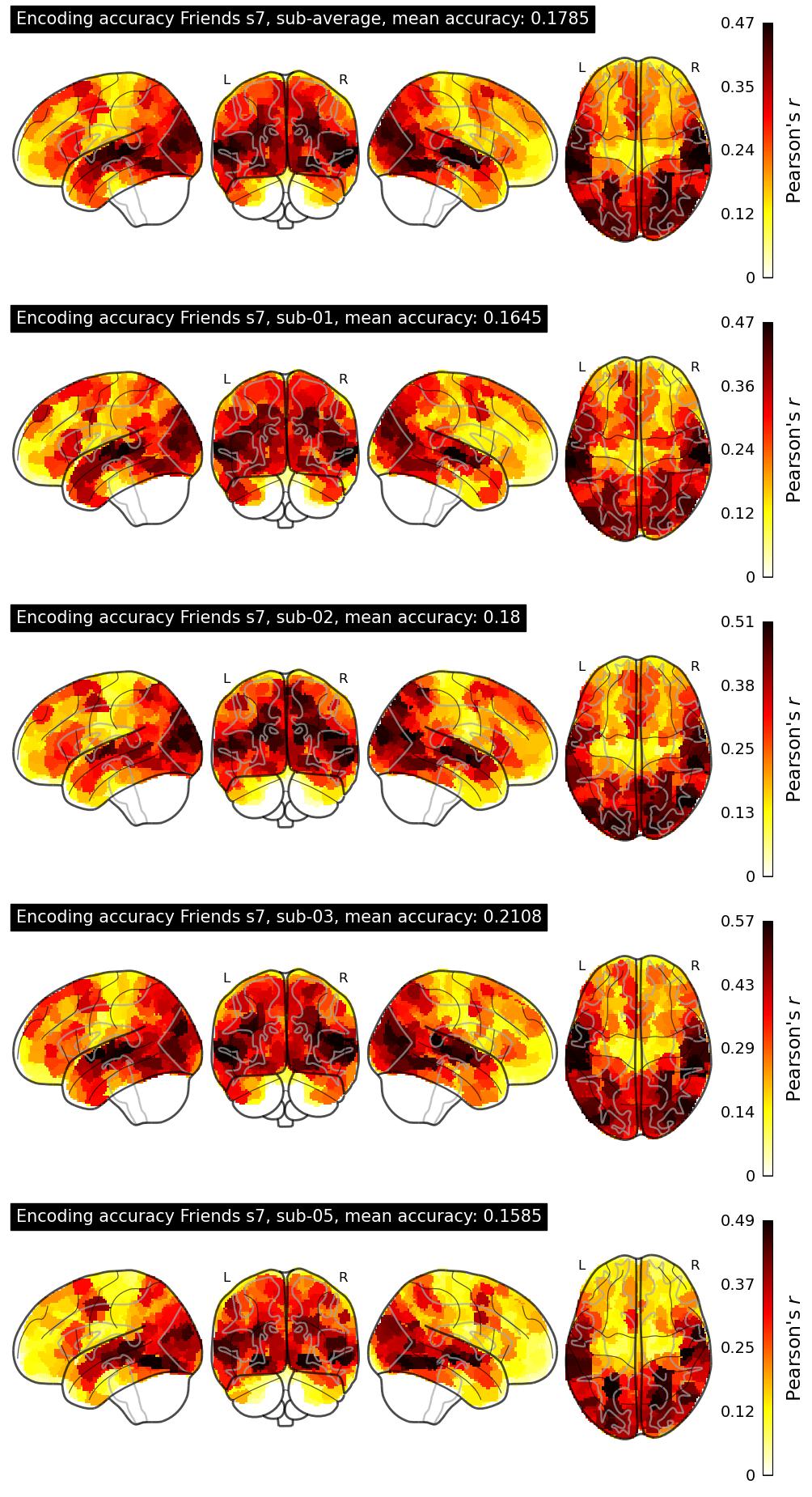
| 58 | wangyt | 0.1790 | Visualization | ||
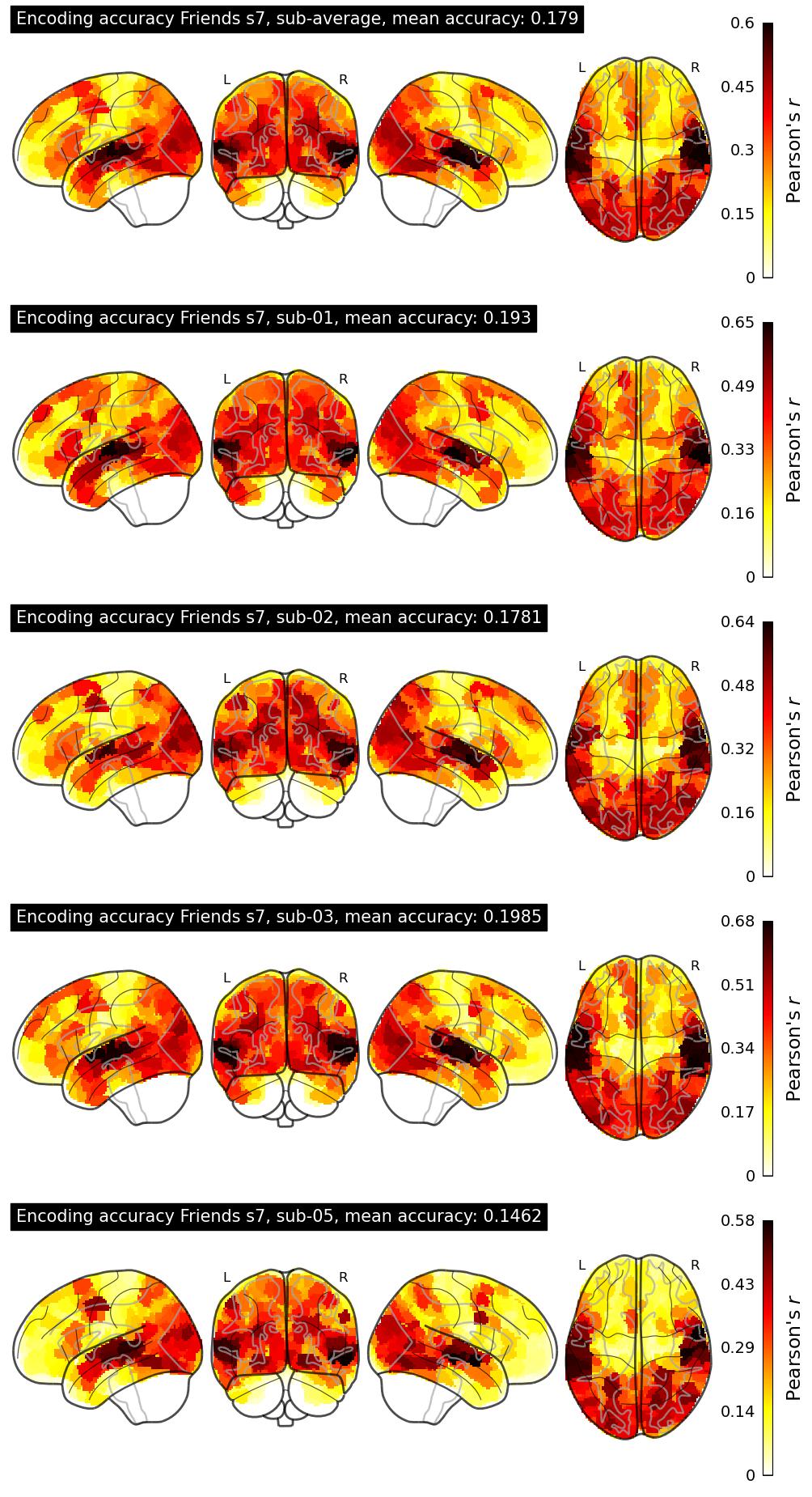
| 59 | yinghua19 | 0.1785 | Visualization | ||
| 60 | barbarioz | 0.1774 | Visualization | ||
| 61 | gabrielkp | 0.1675 | Visualization | ||
| 62 | sanpdy | 0.1306 | Visualization | ||
| 63 | BOSSlab | 0.1096 | Visualization | ||
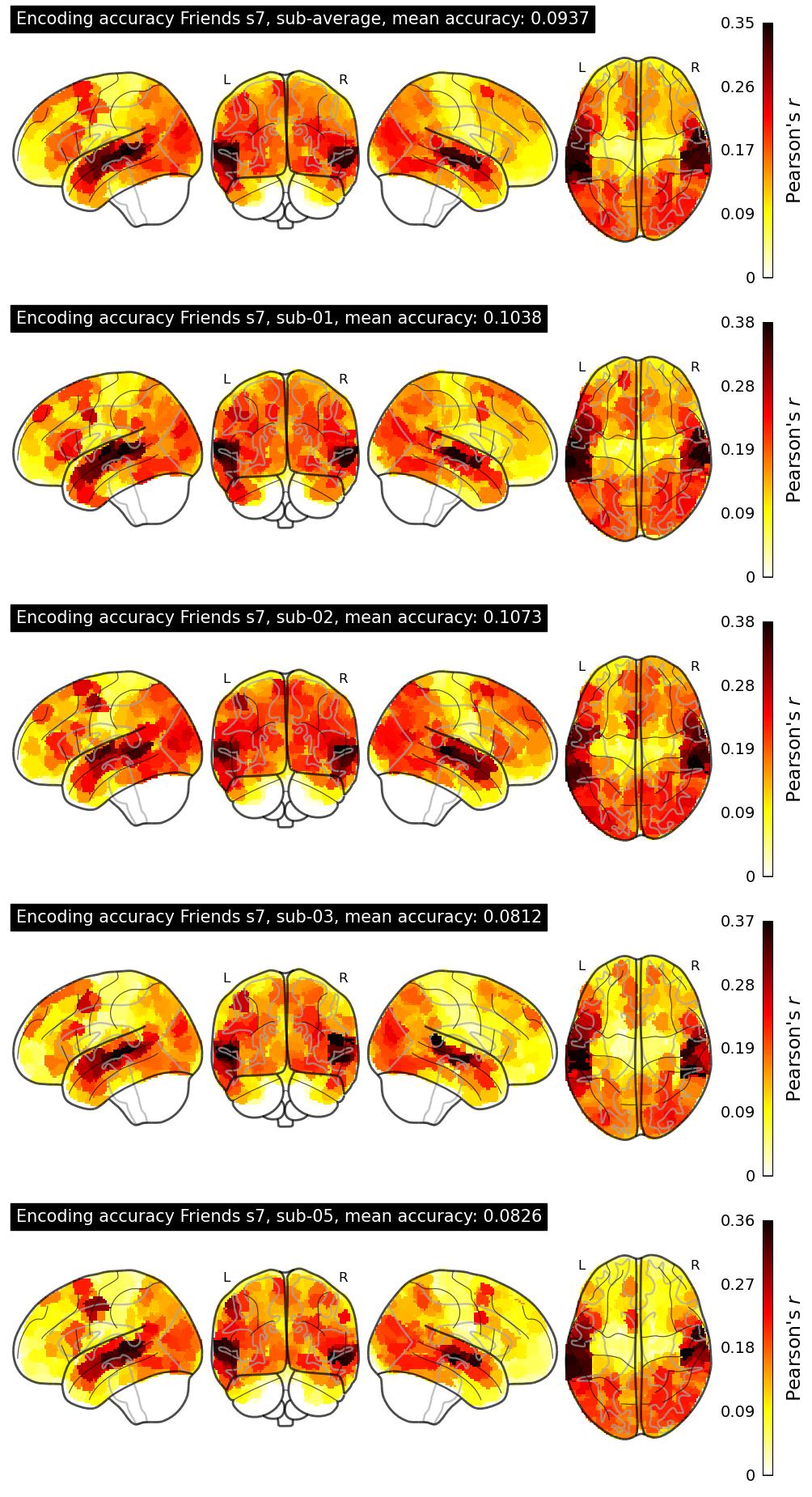
| 64 | yyyyyyyyyyy | 0.0937 | Visualization | ||
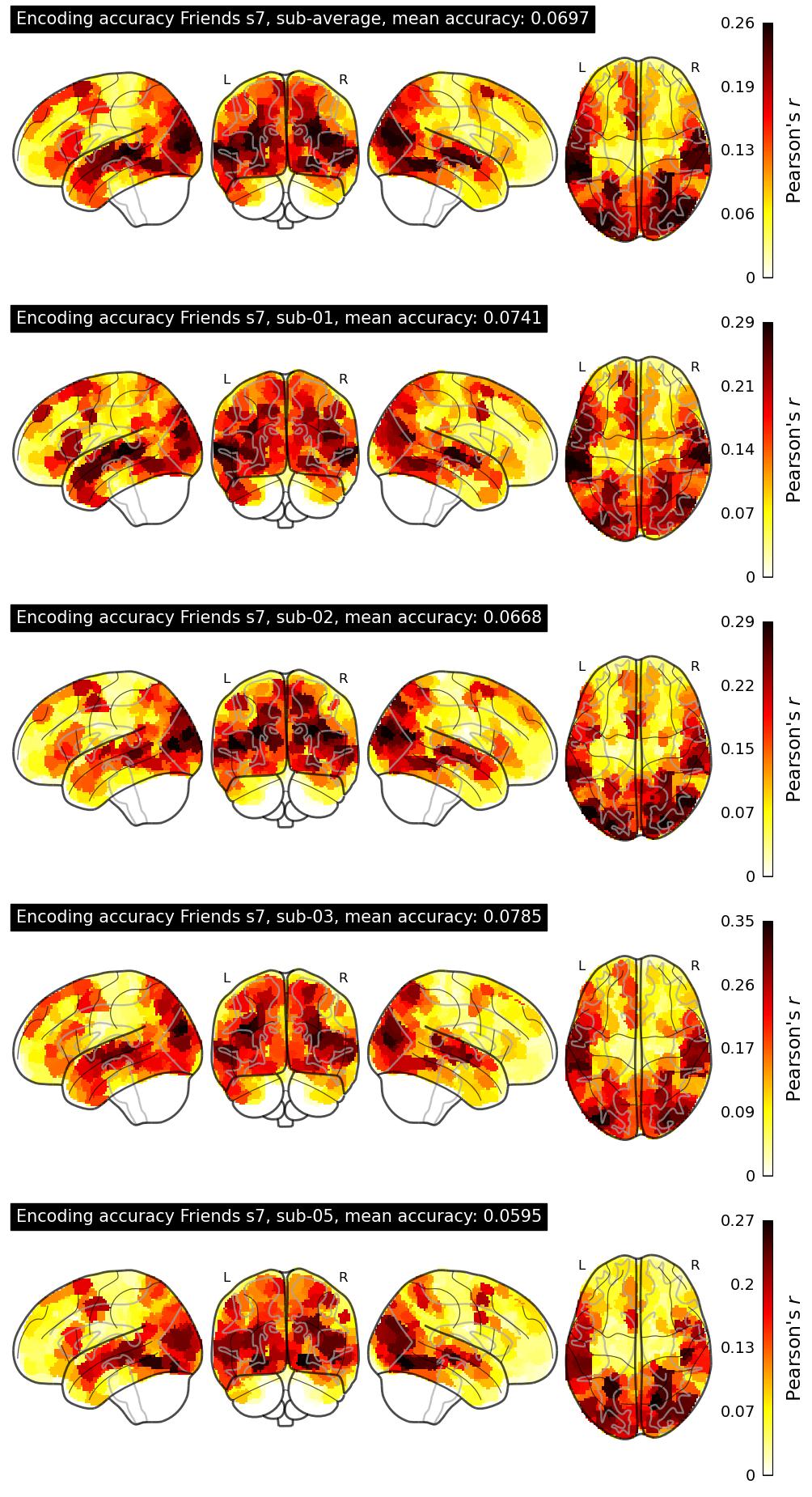
| 65 | marroth93 | 0.0697 | Visualization | ||
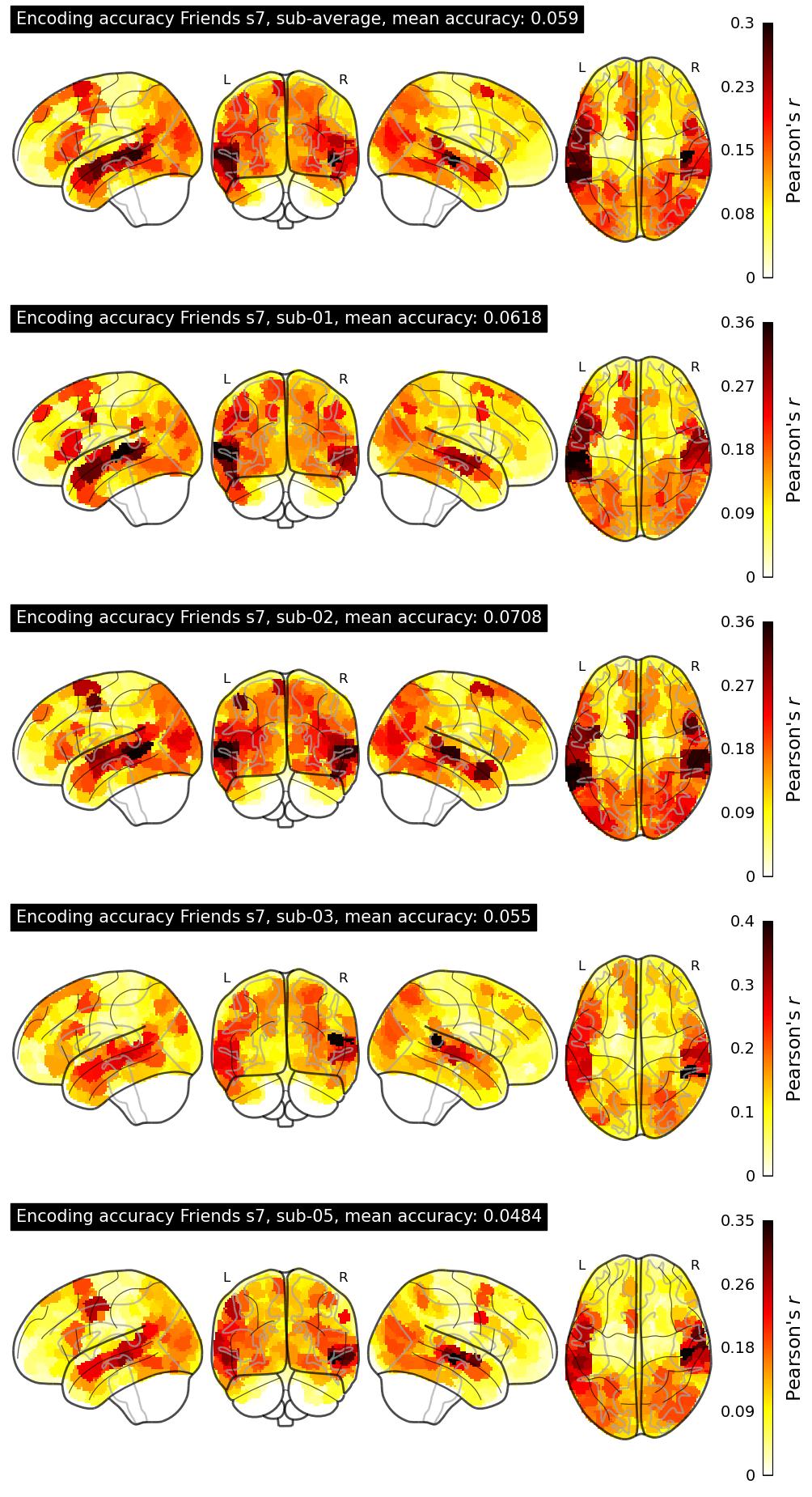
| 66 | projectpioneer | 0.0590 | Visualization | ||
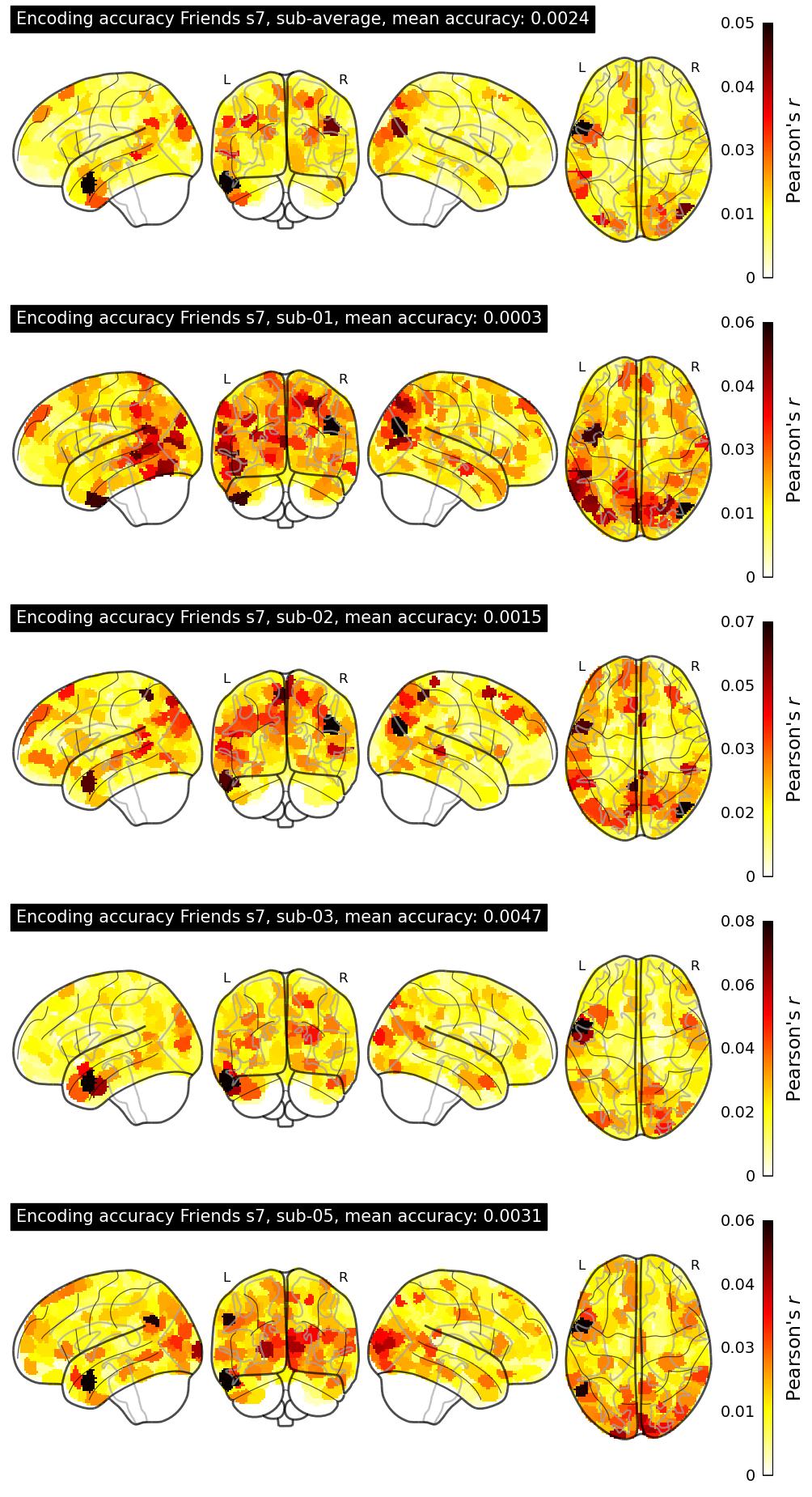
| 67 | NClab | 0.0024 | Visualization |
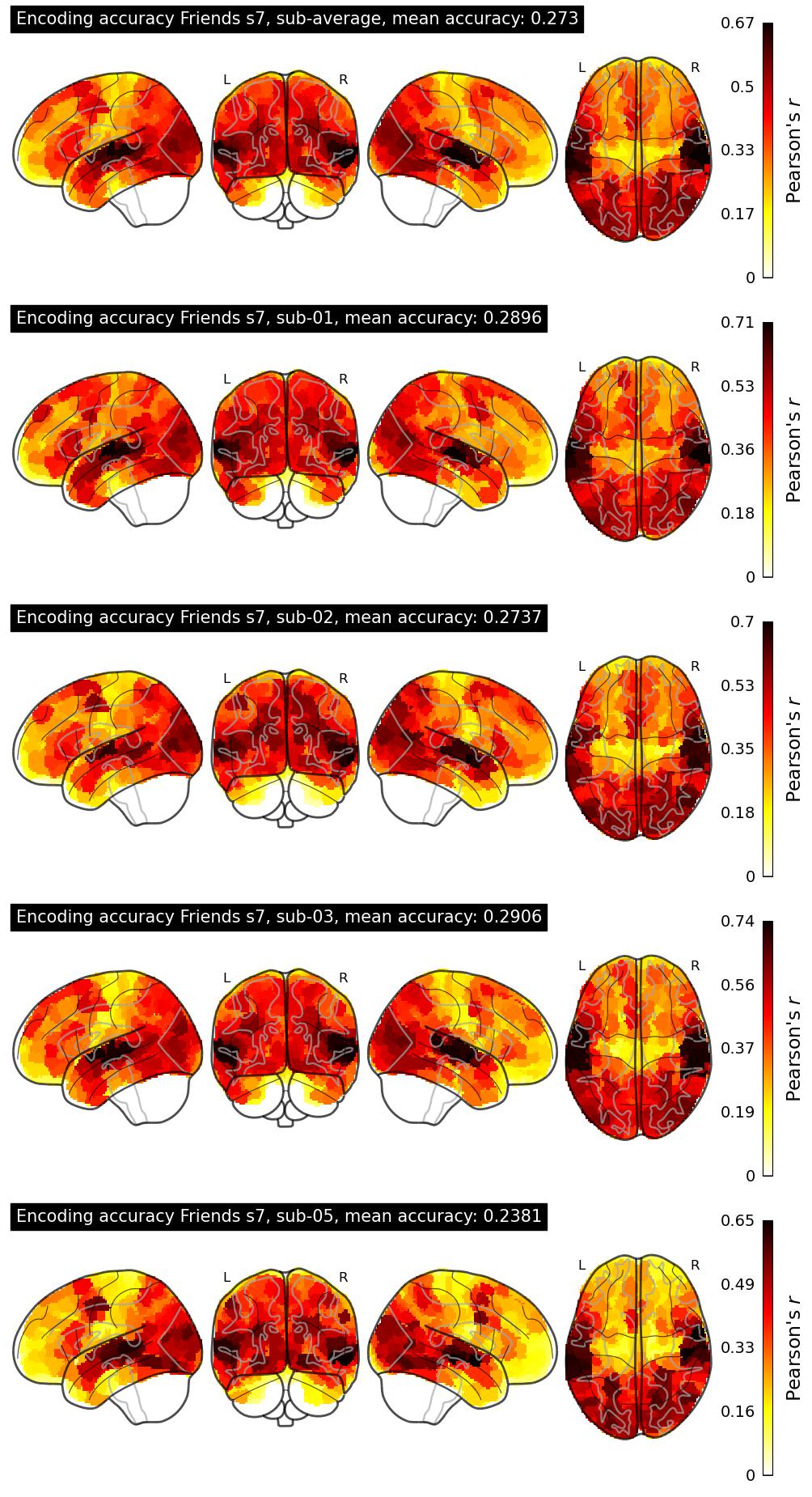
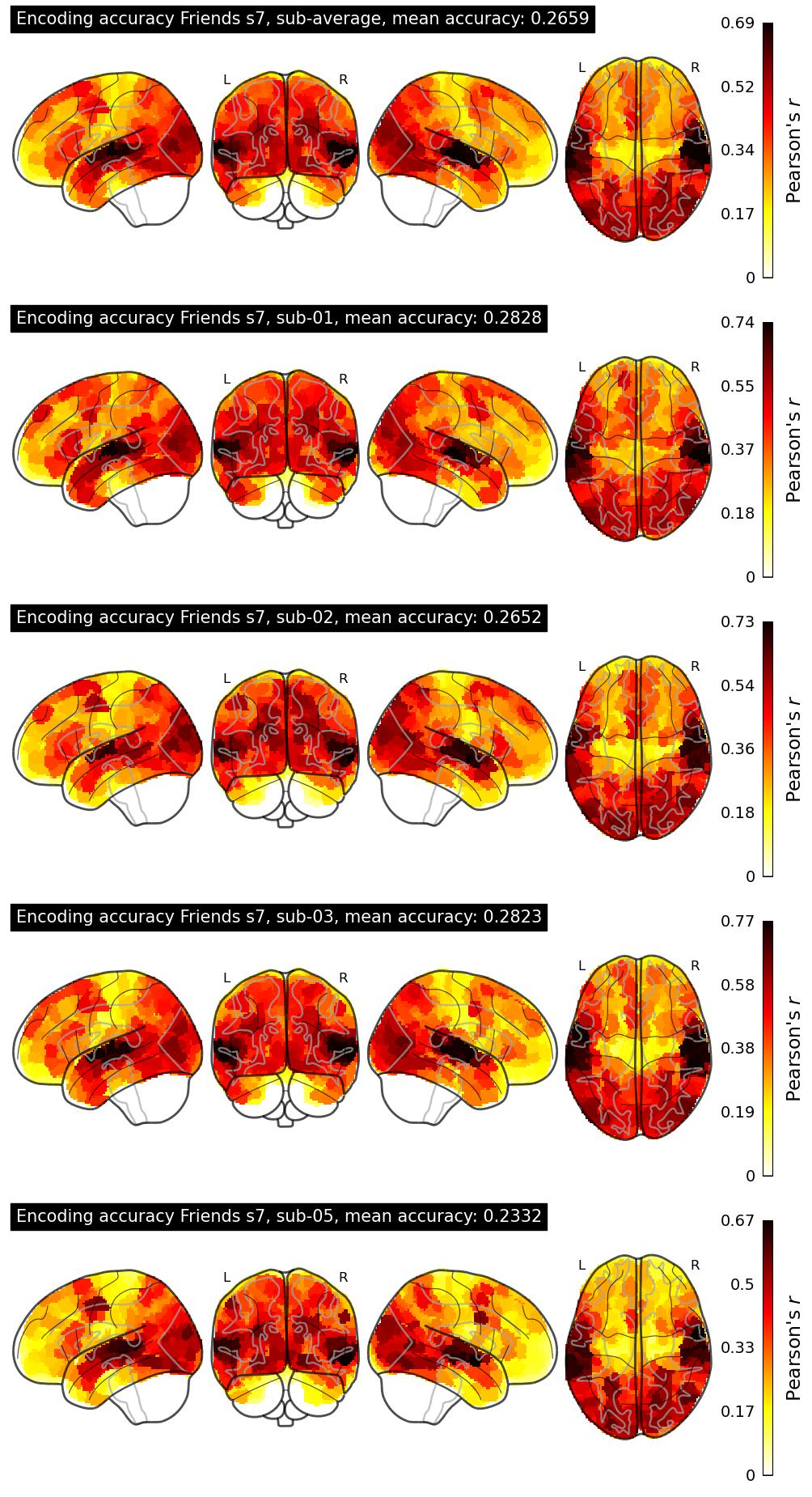
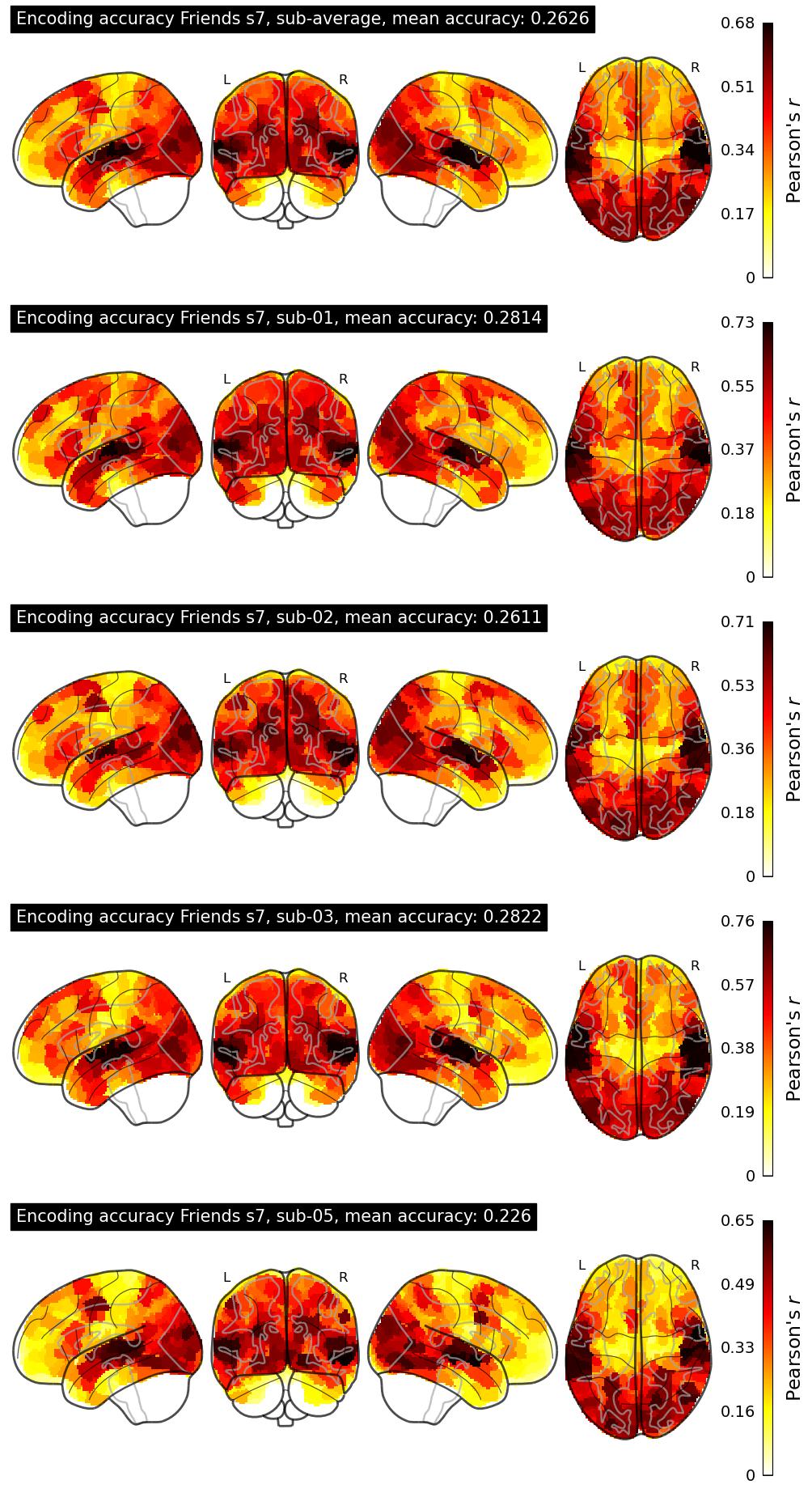
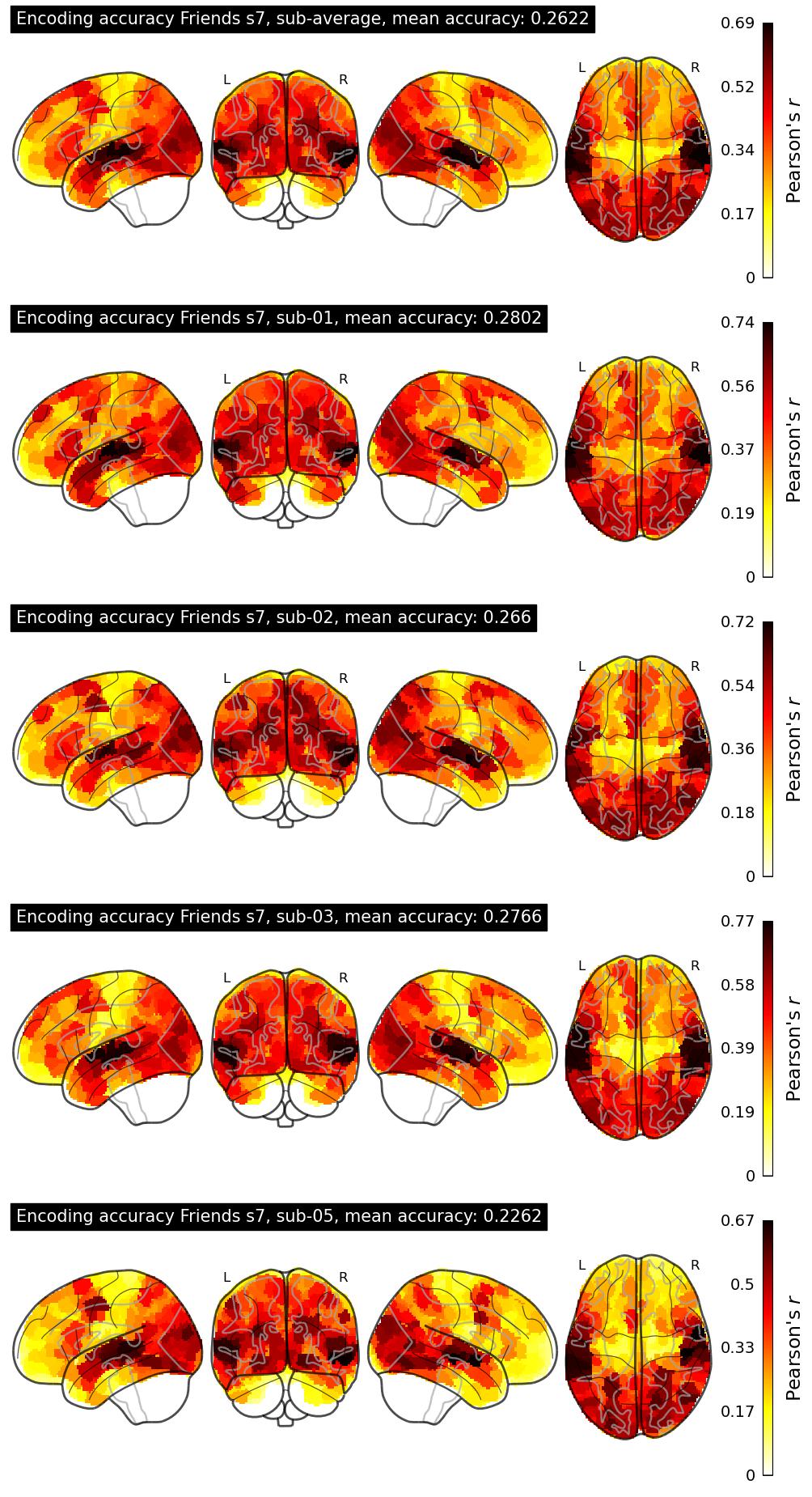
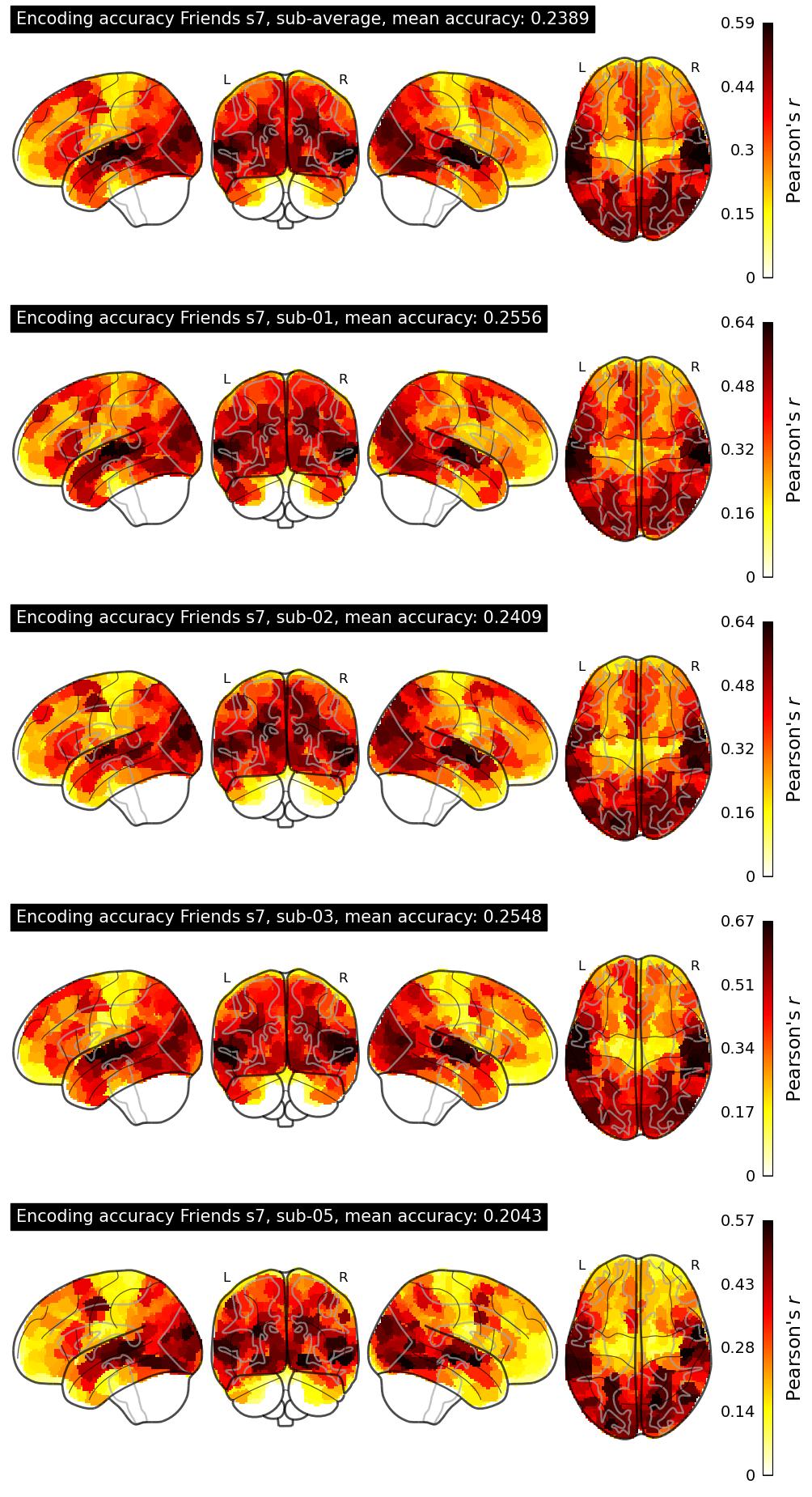
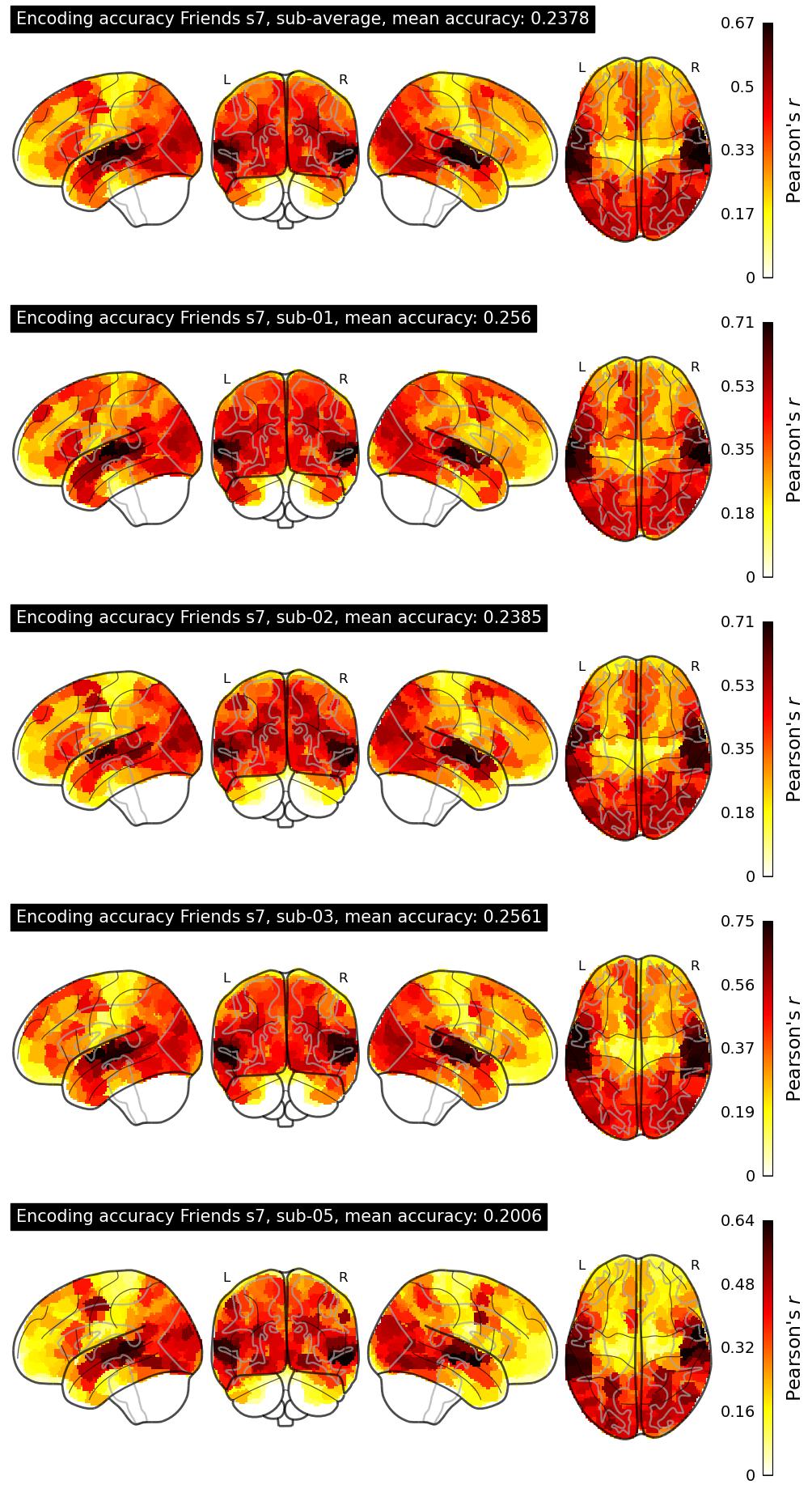
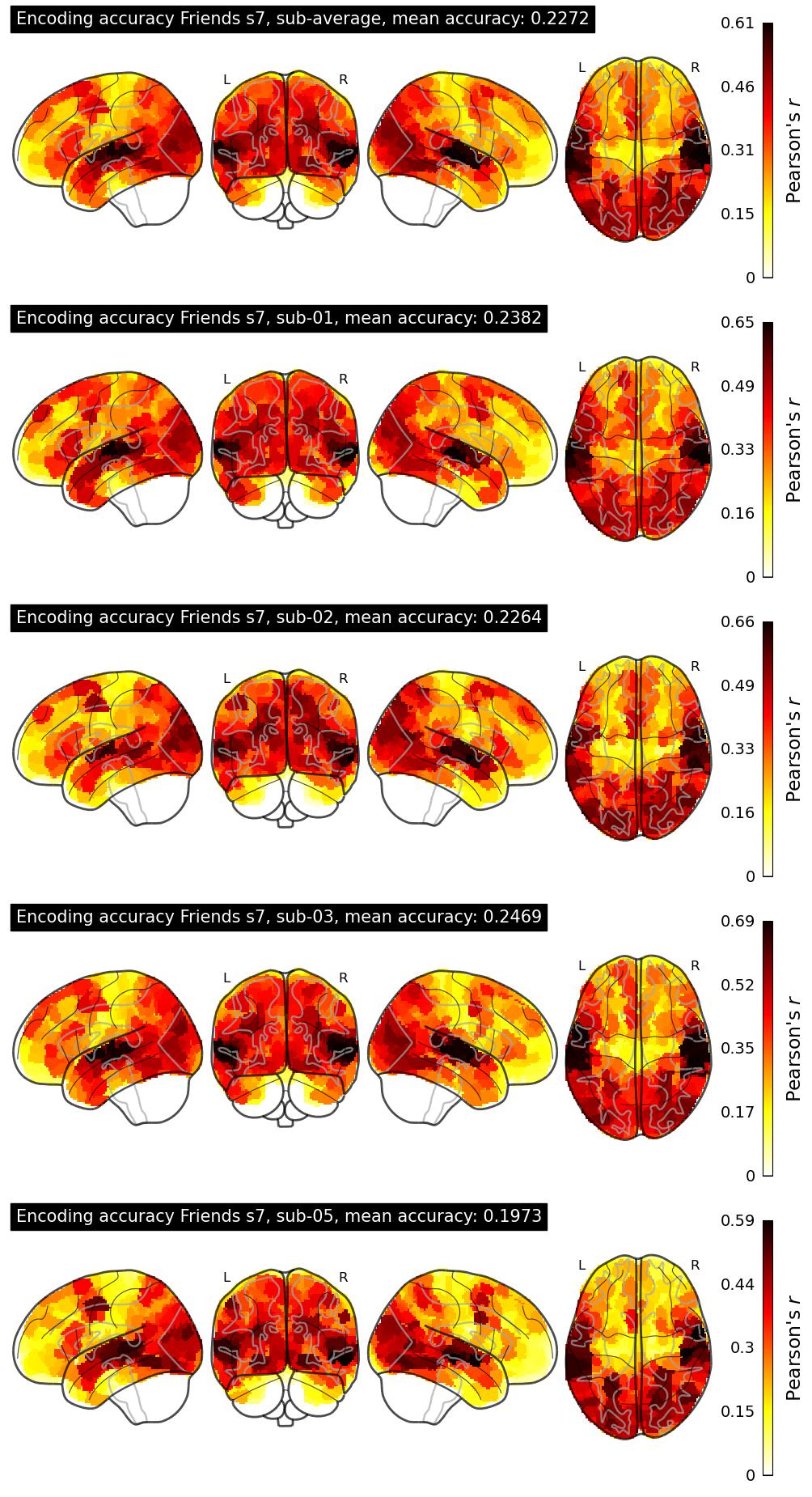
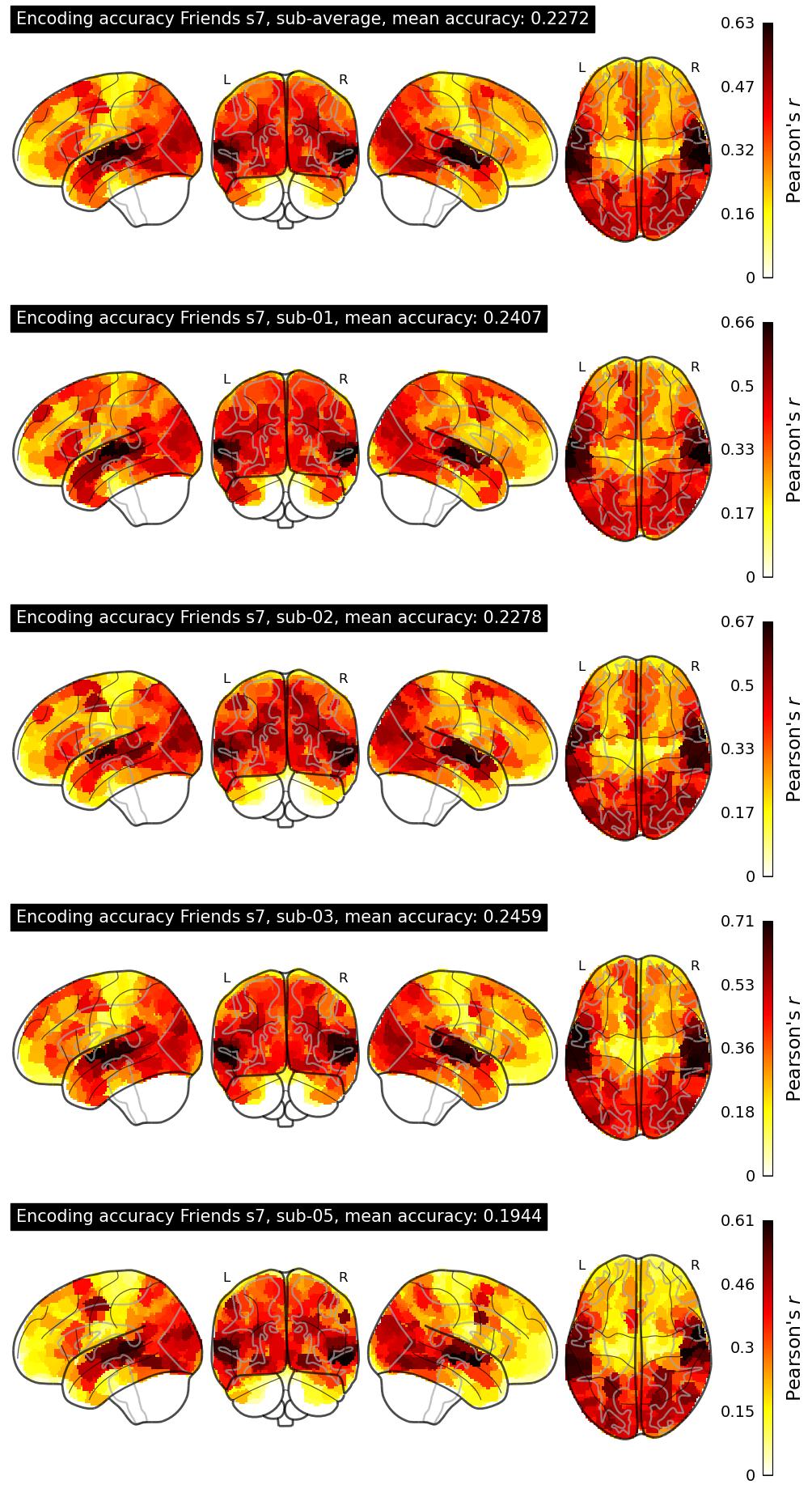
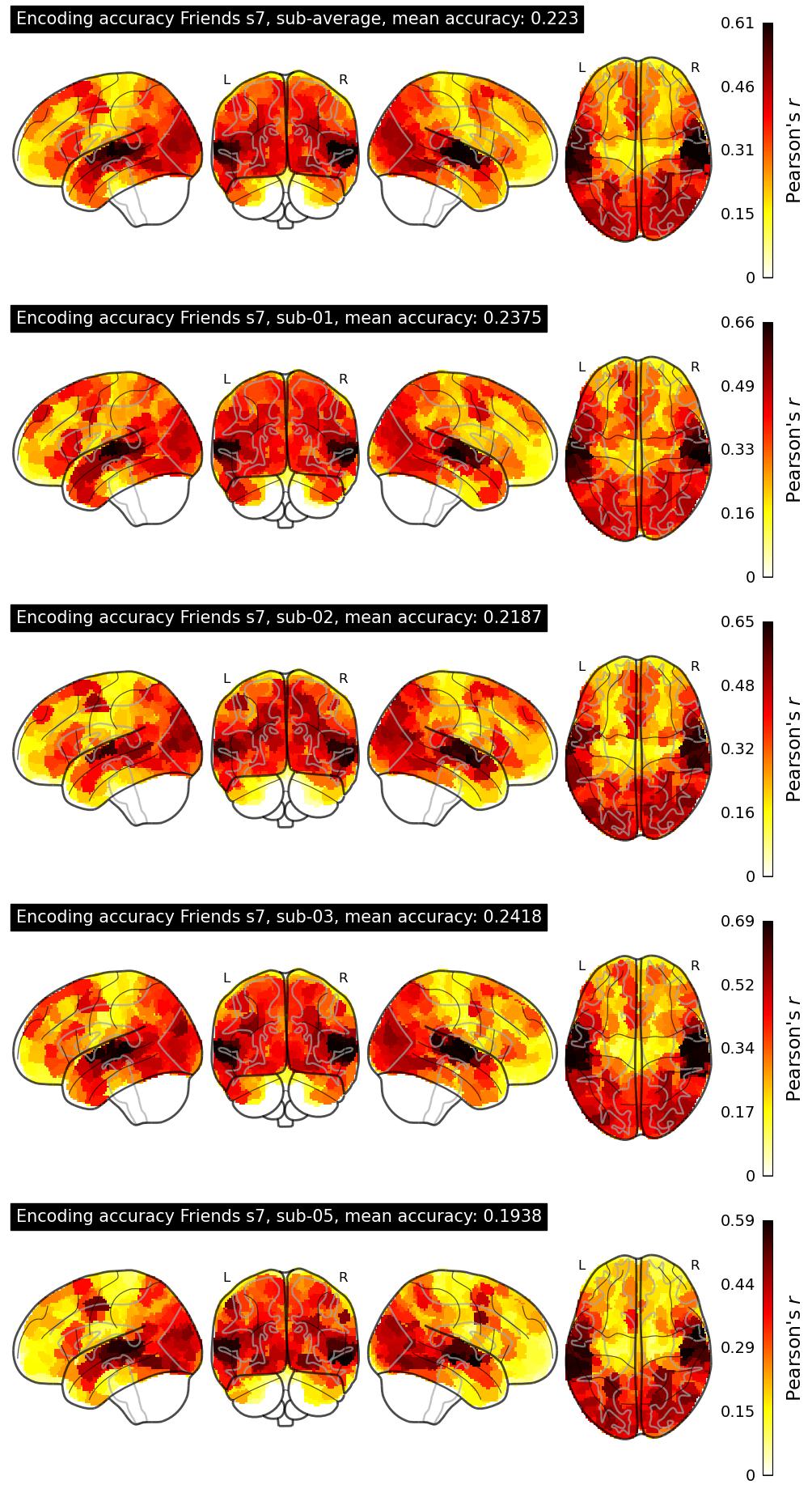
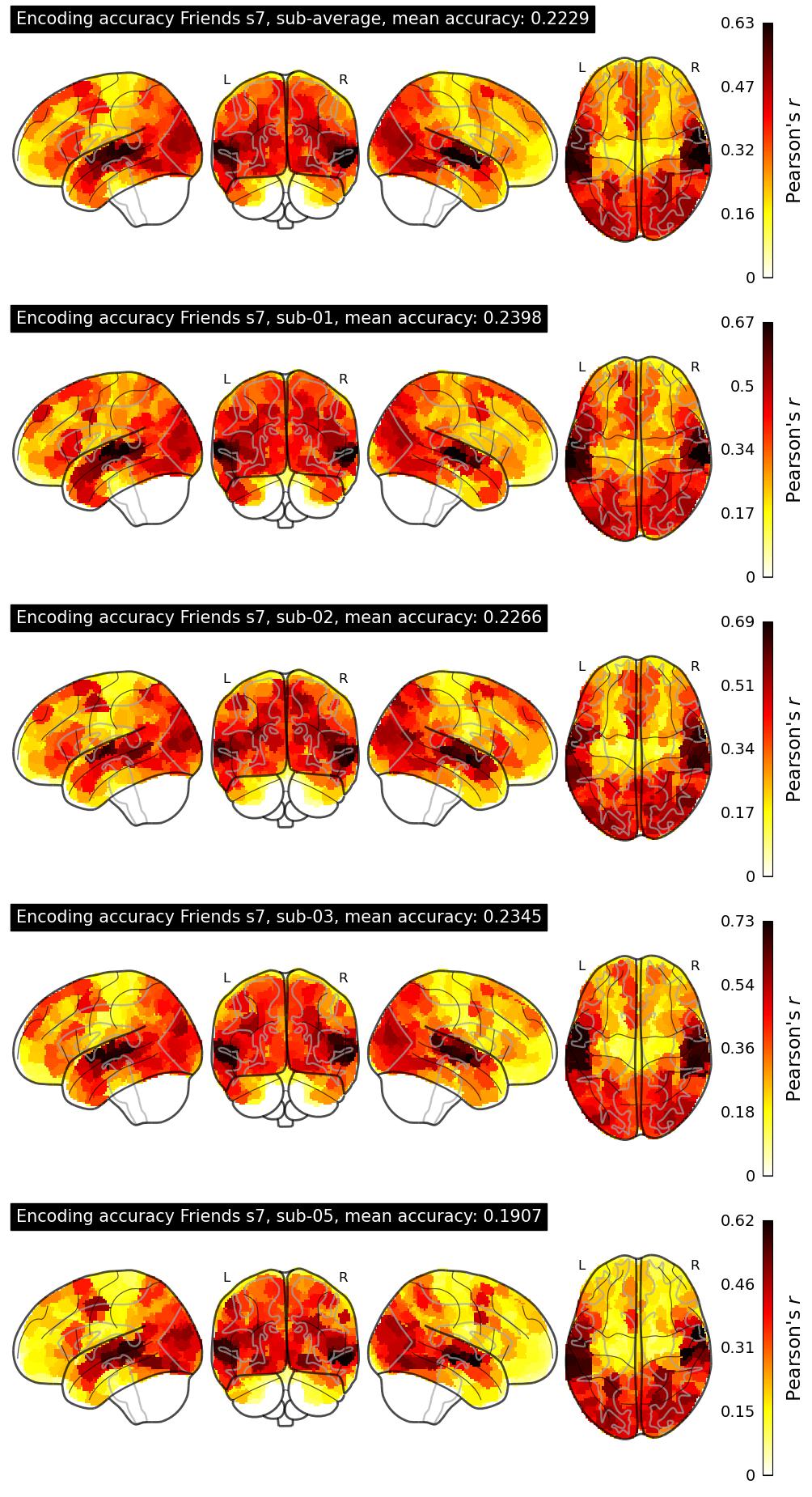
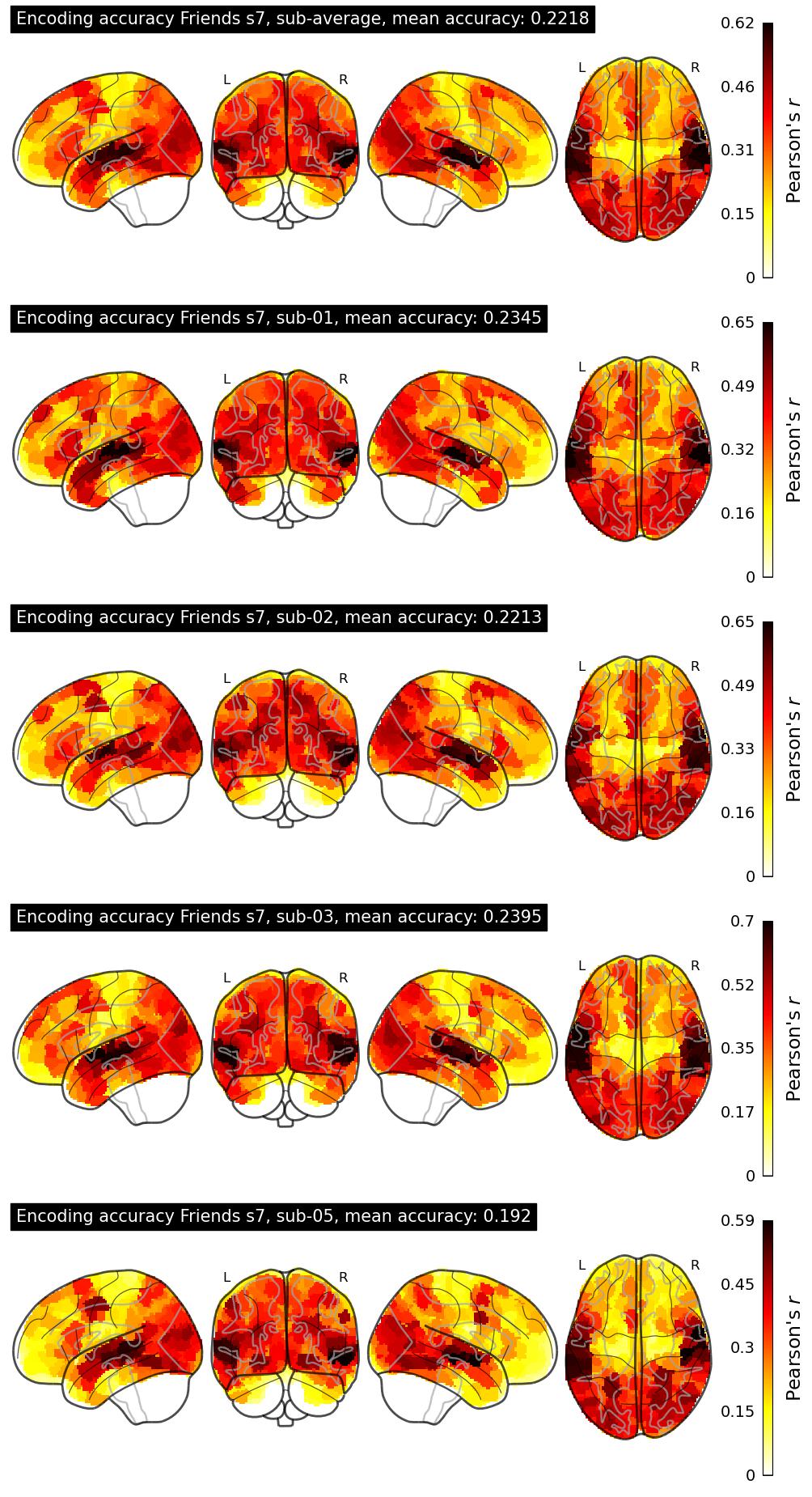
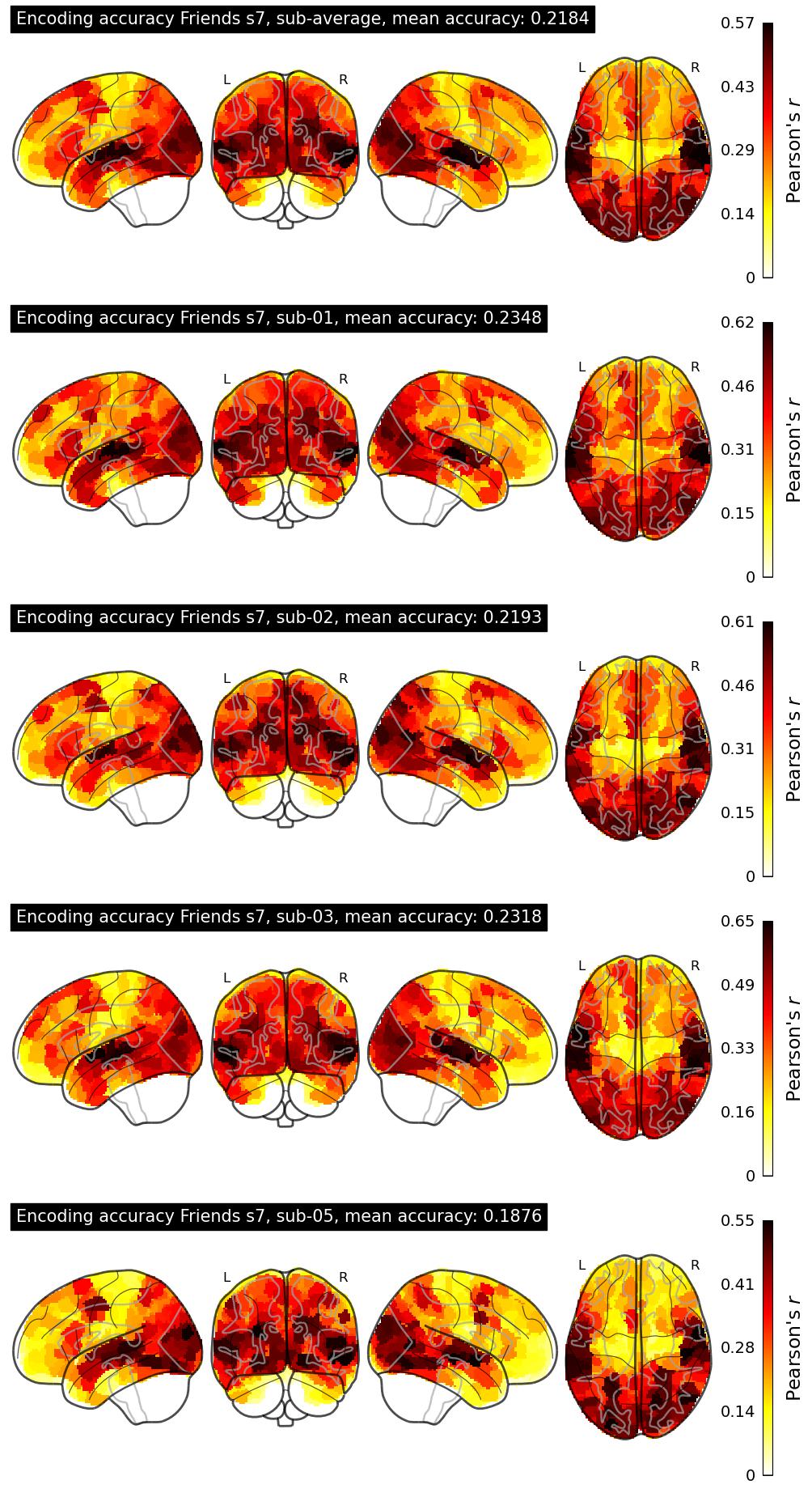
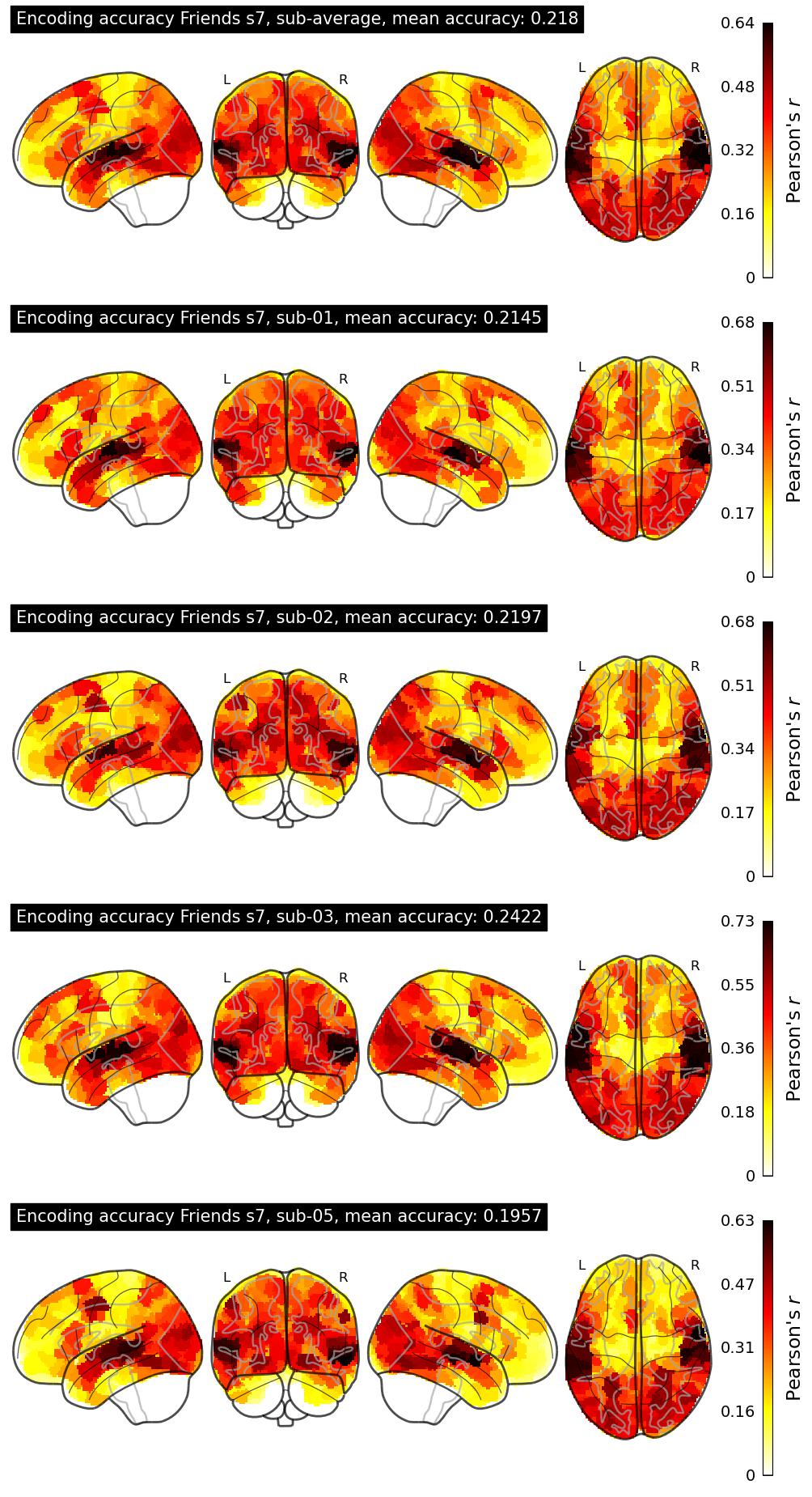
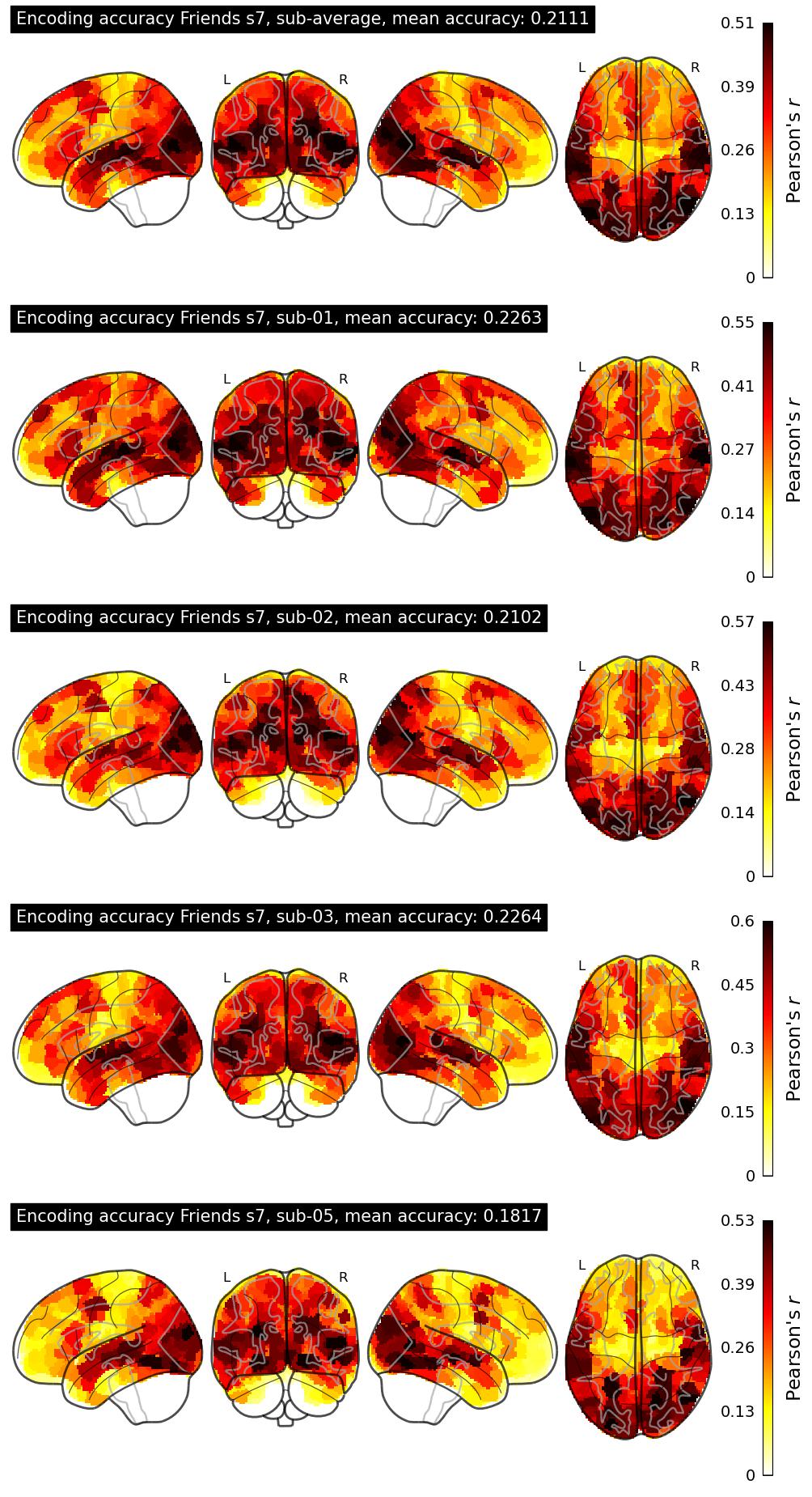
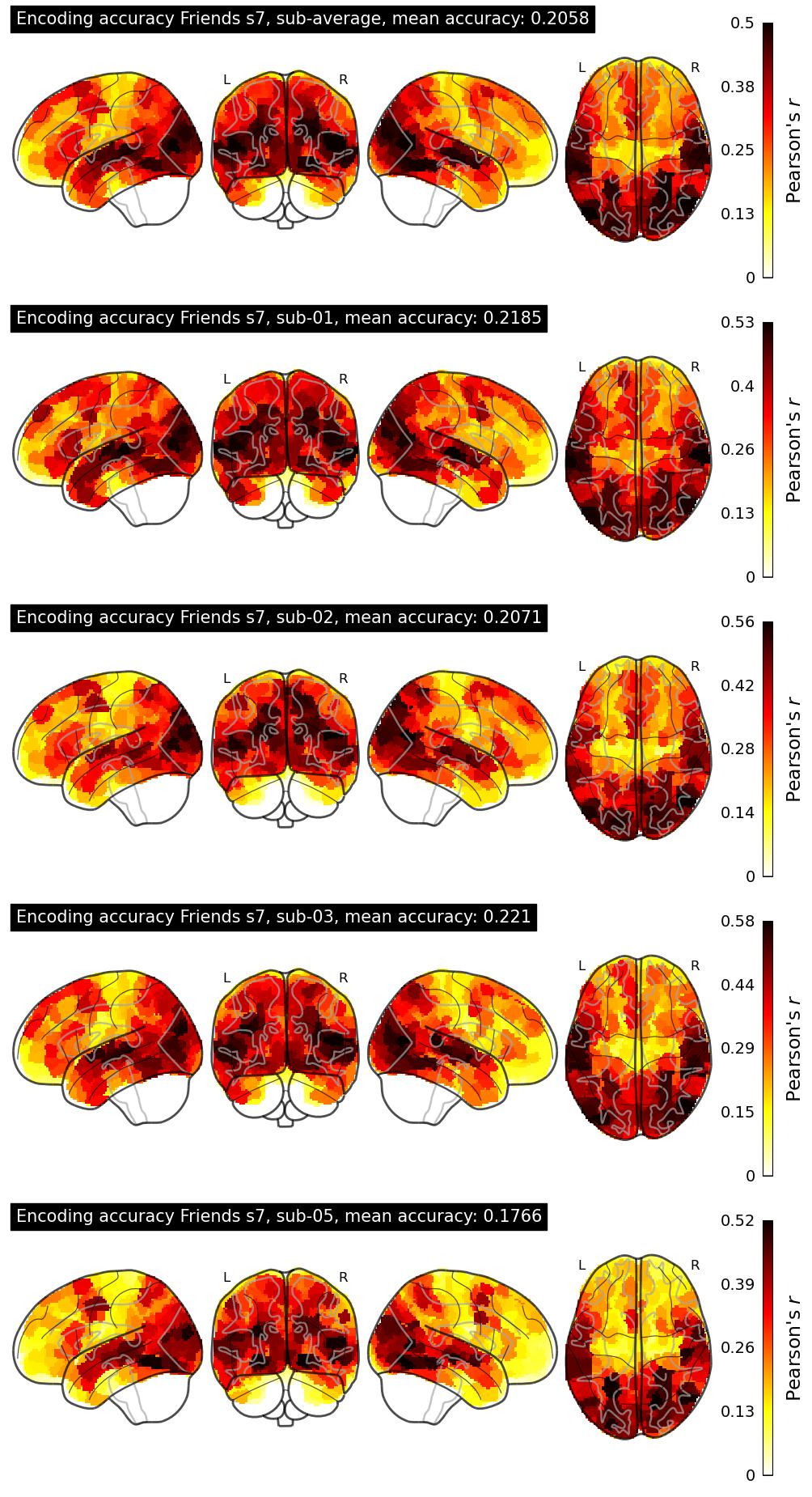
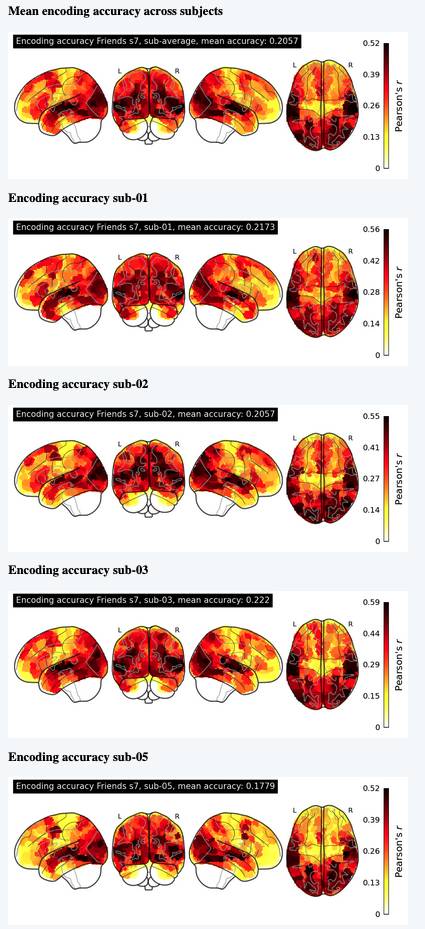
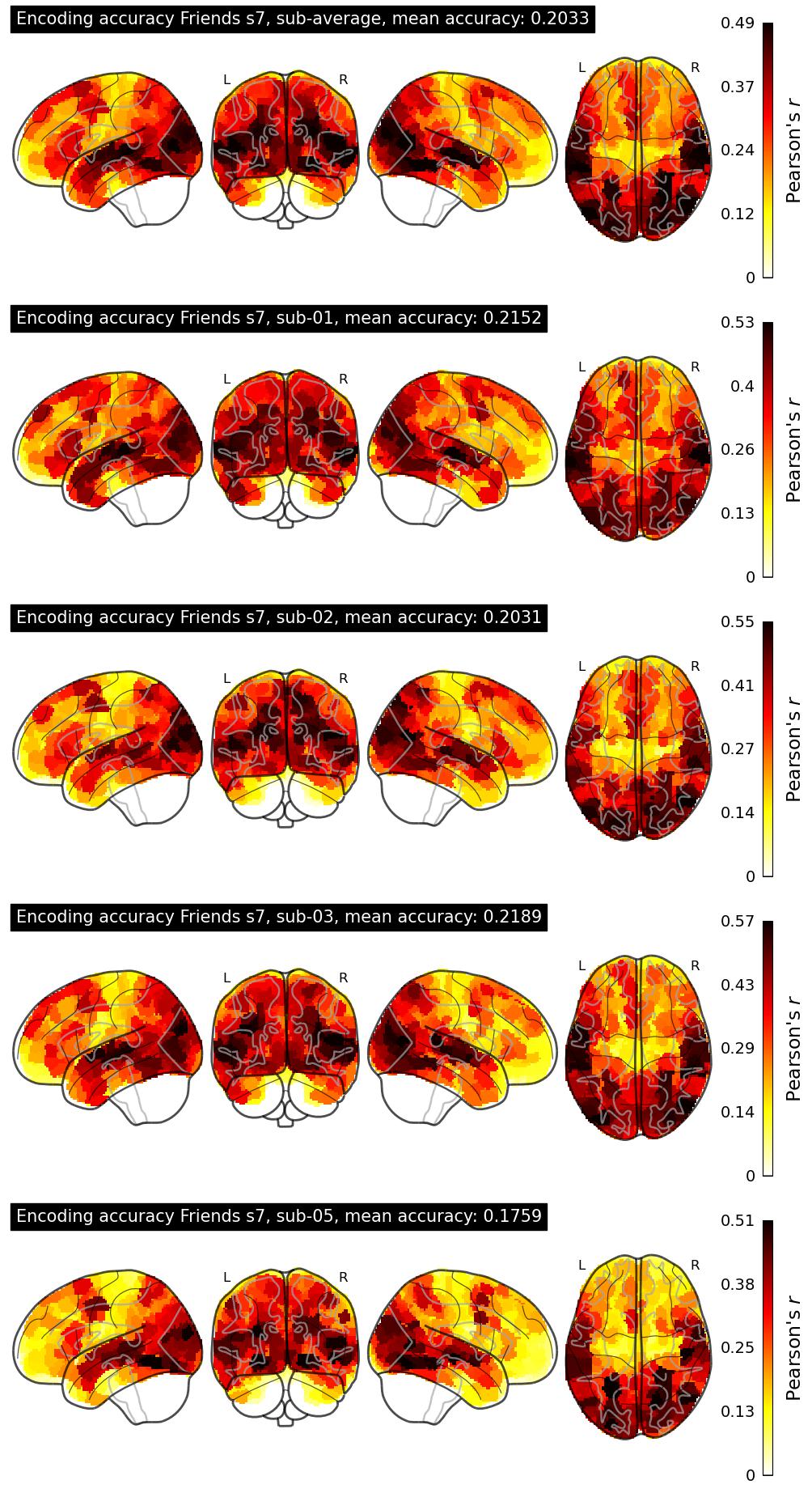
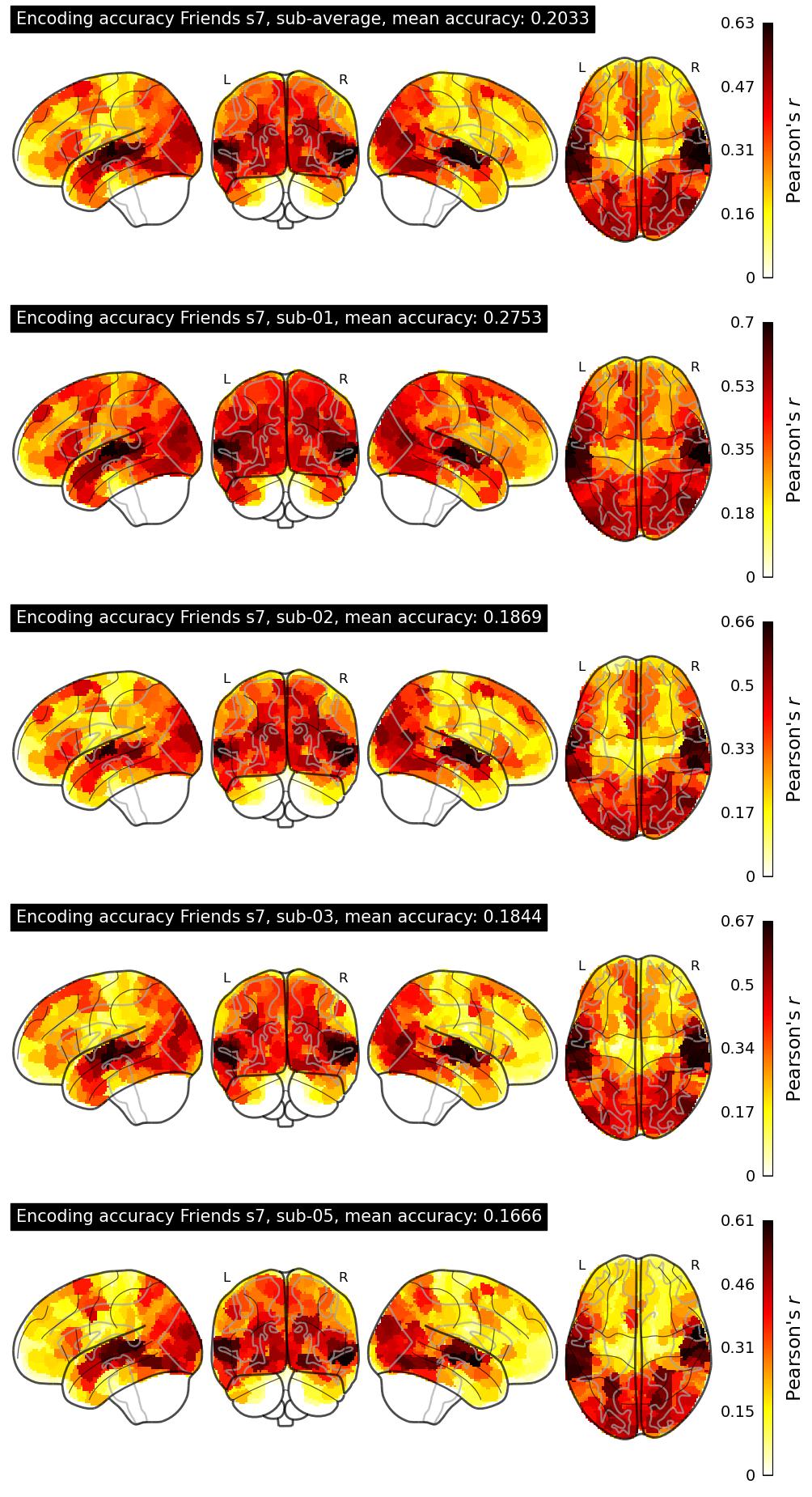
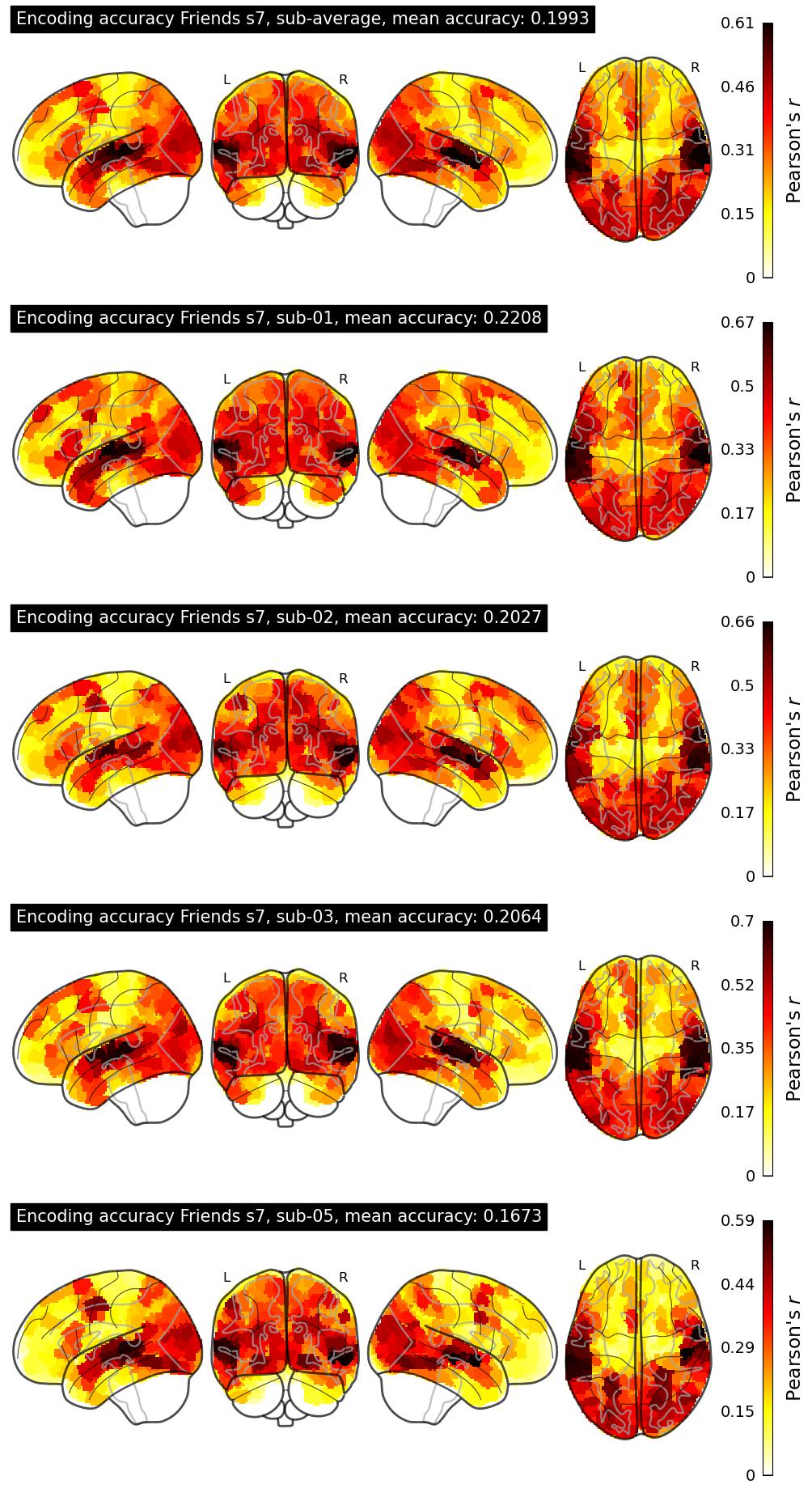
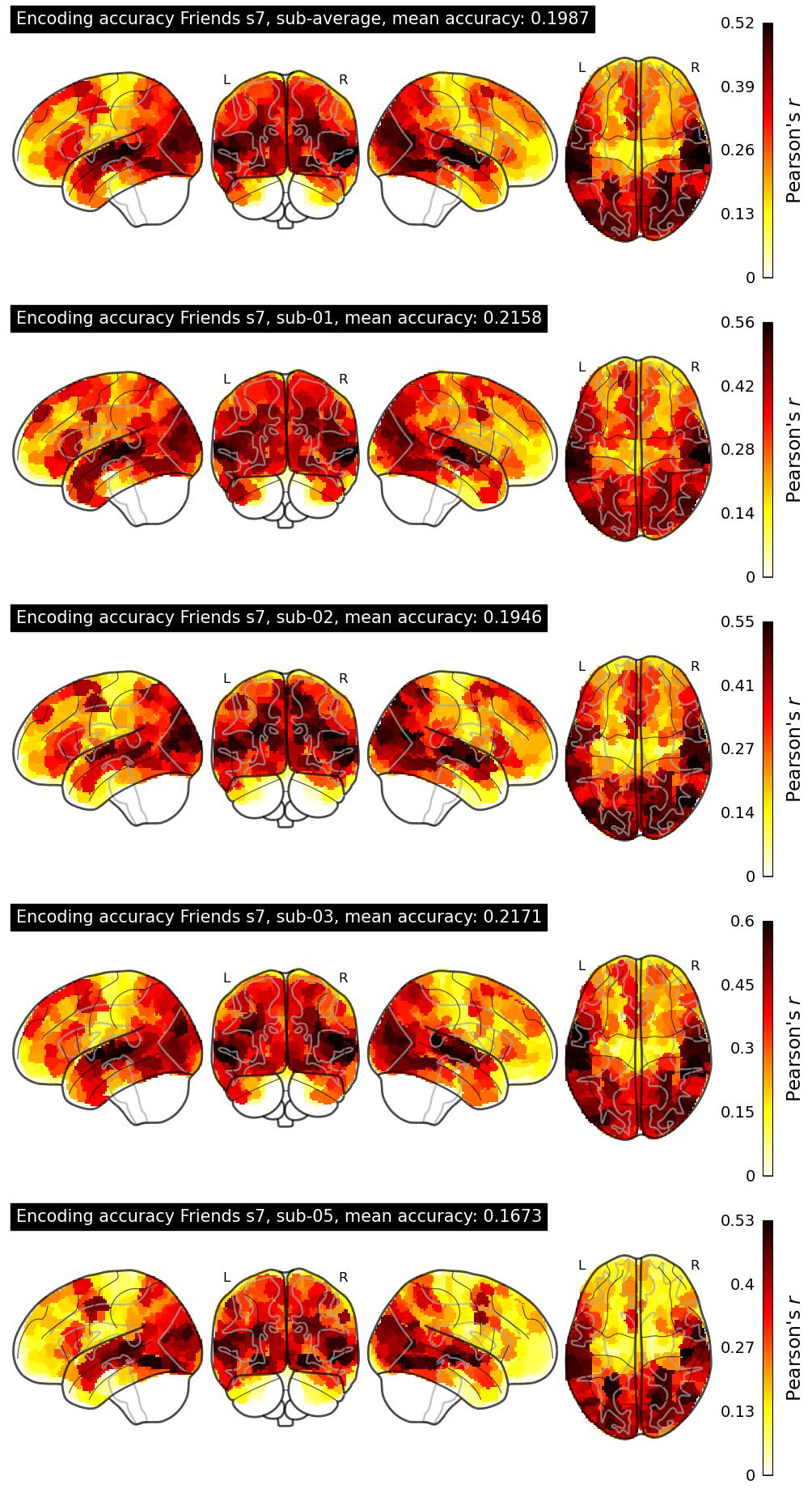
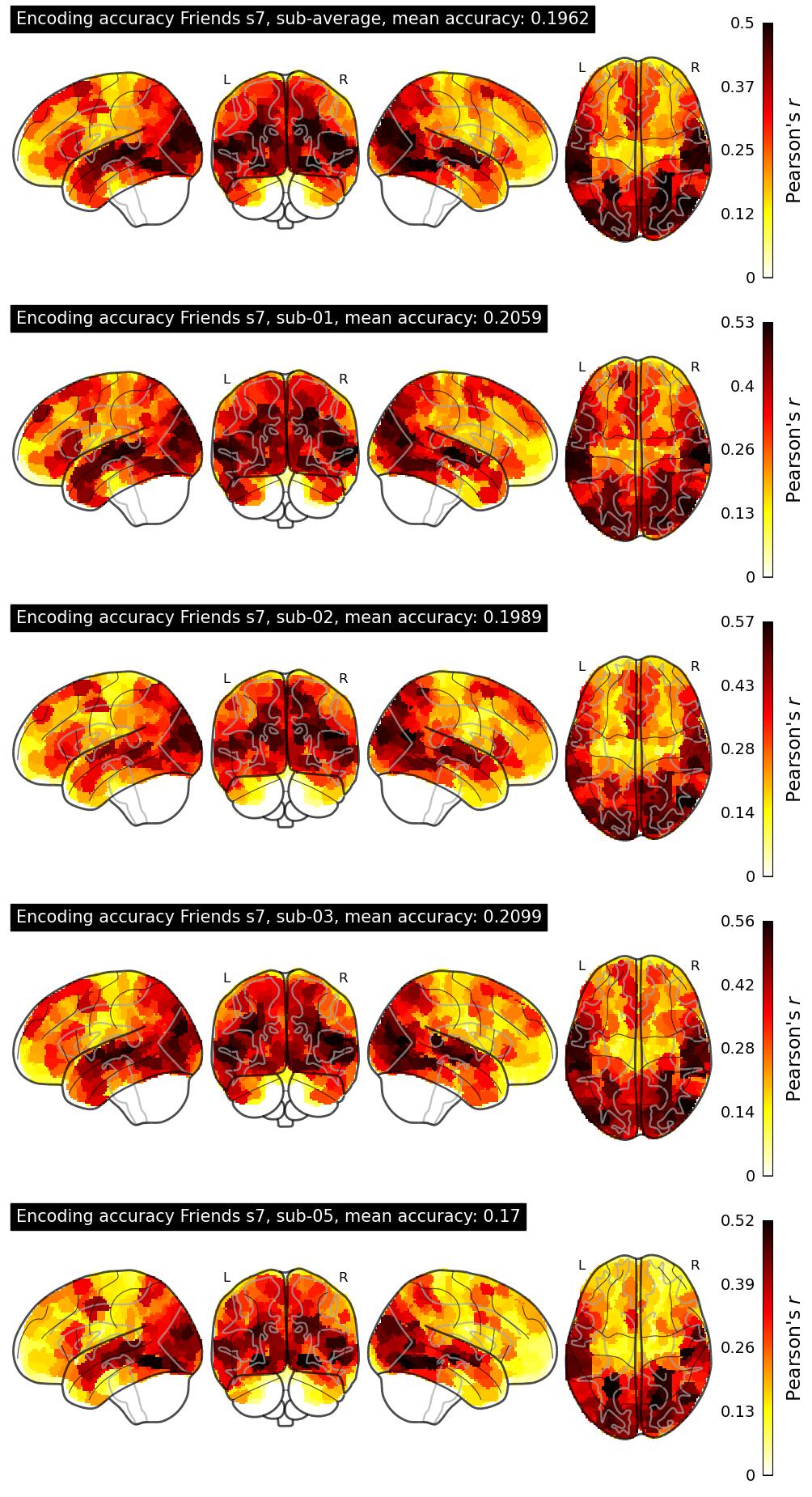
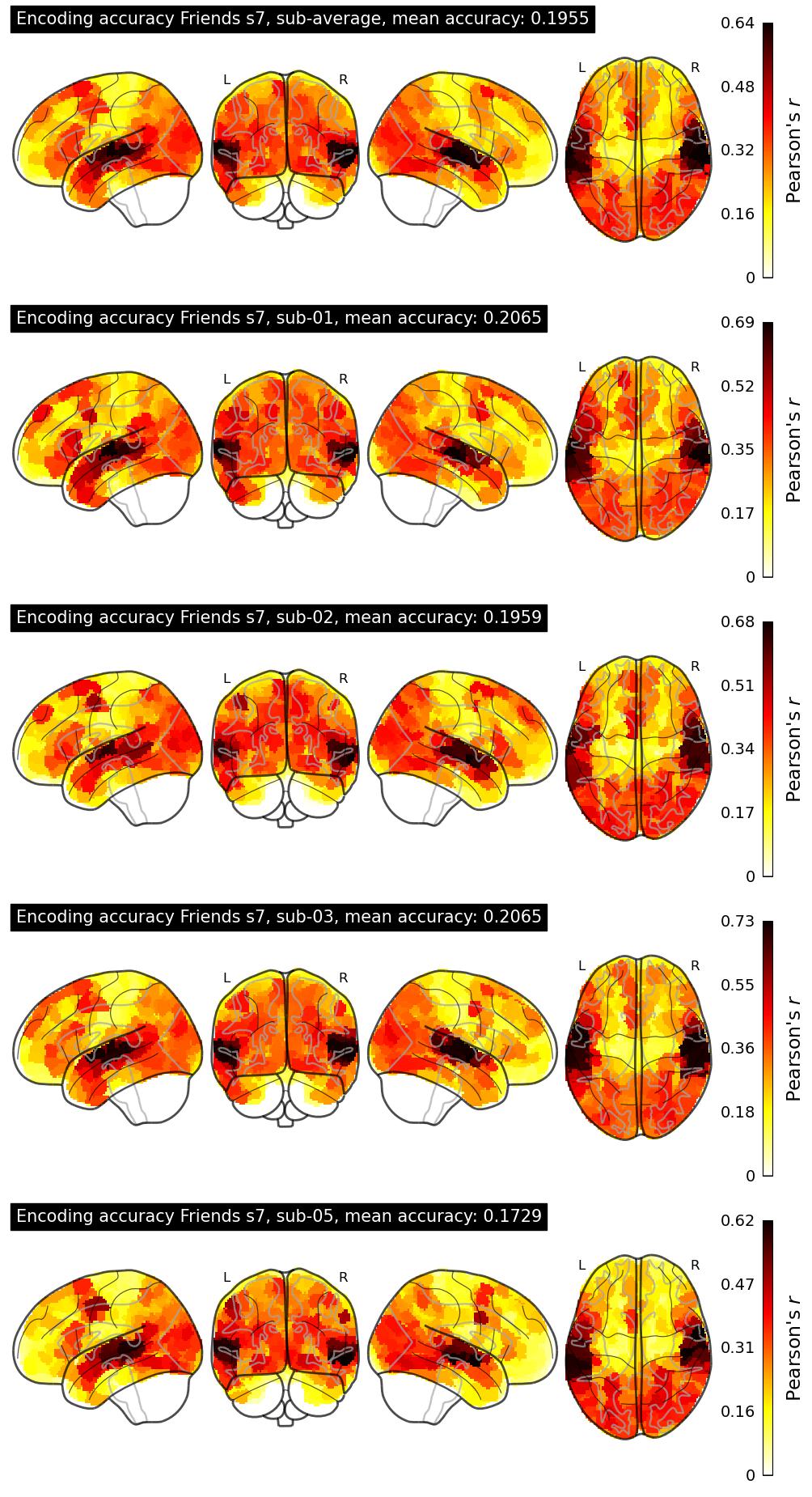
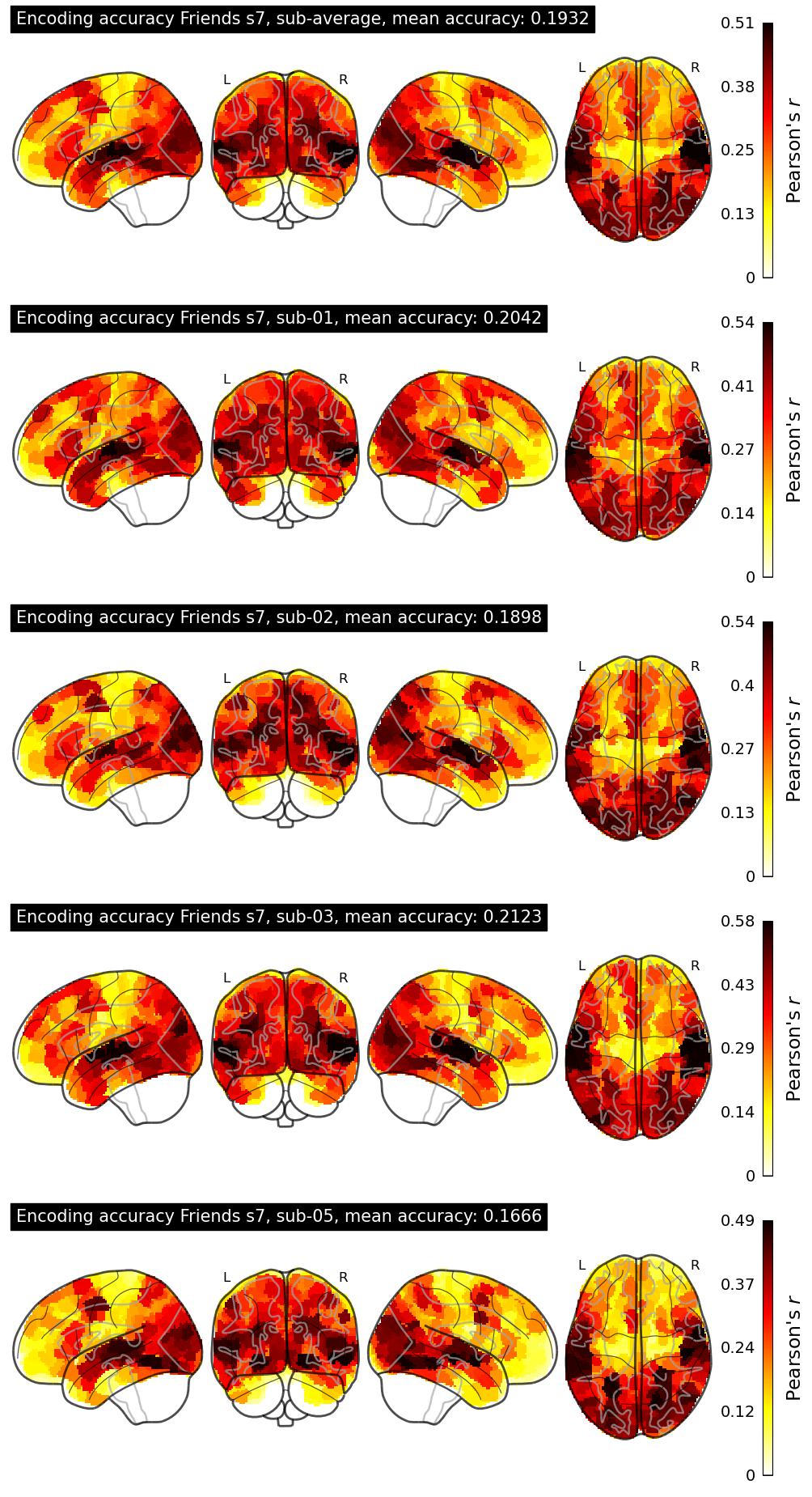
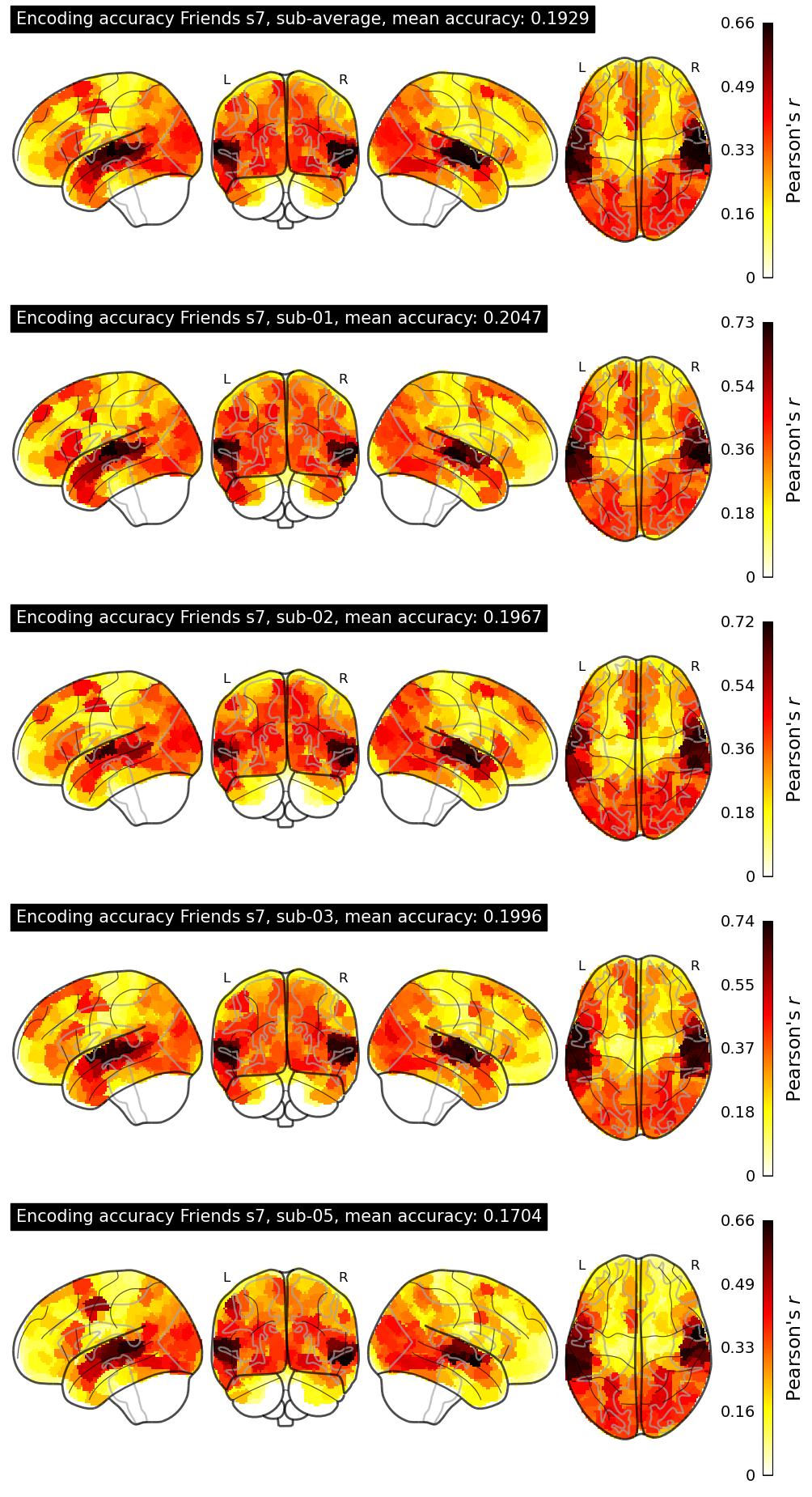
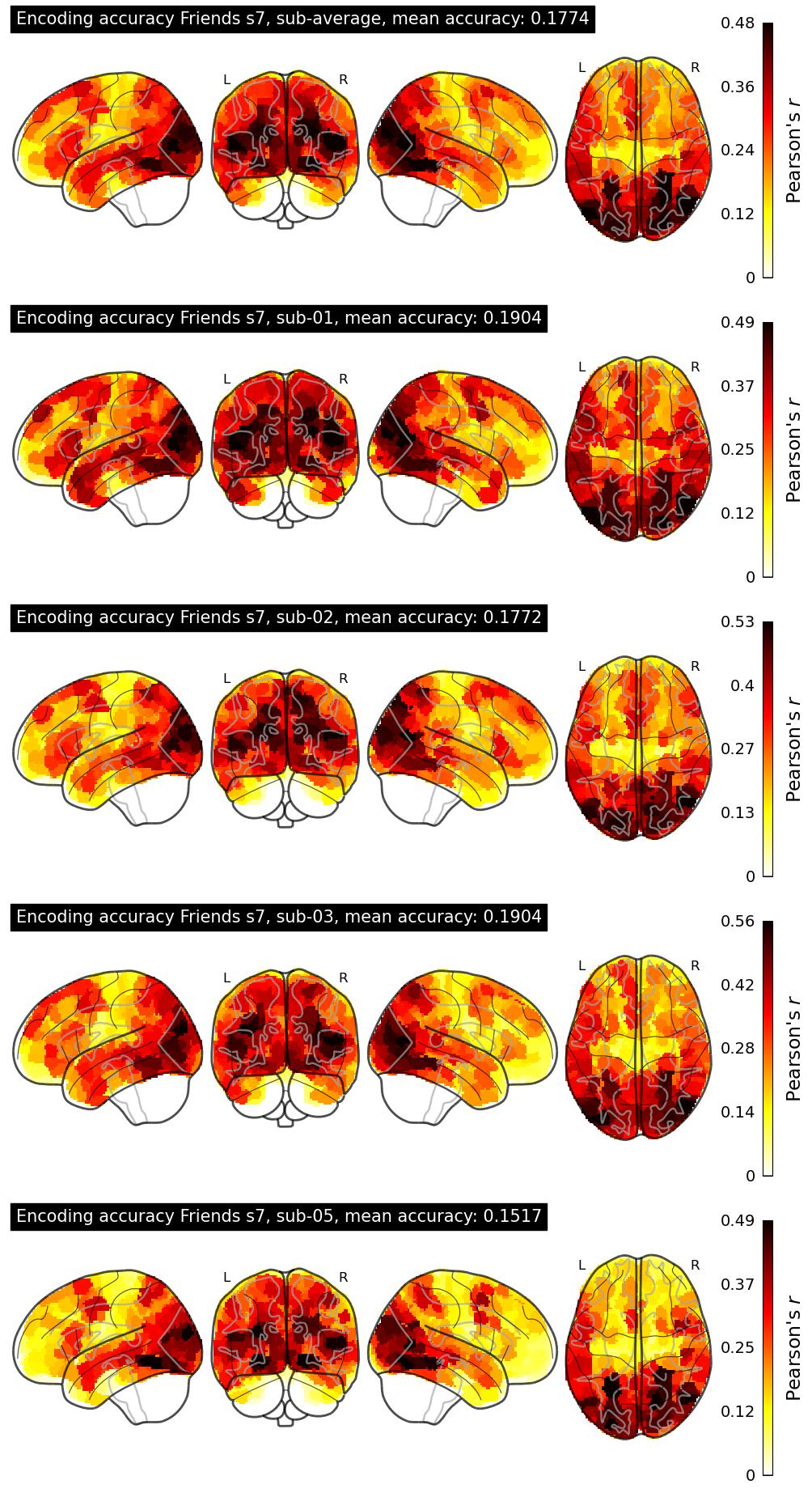
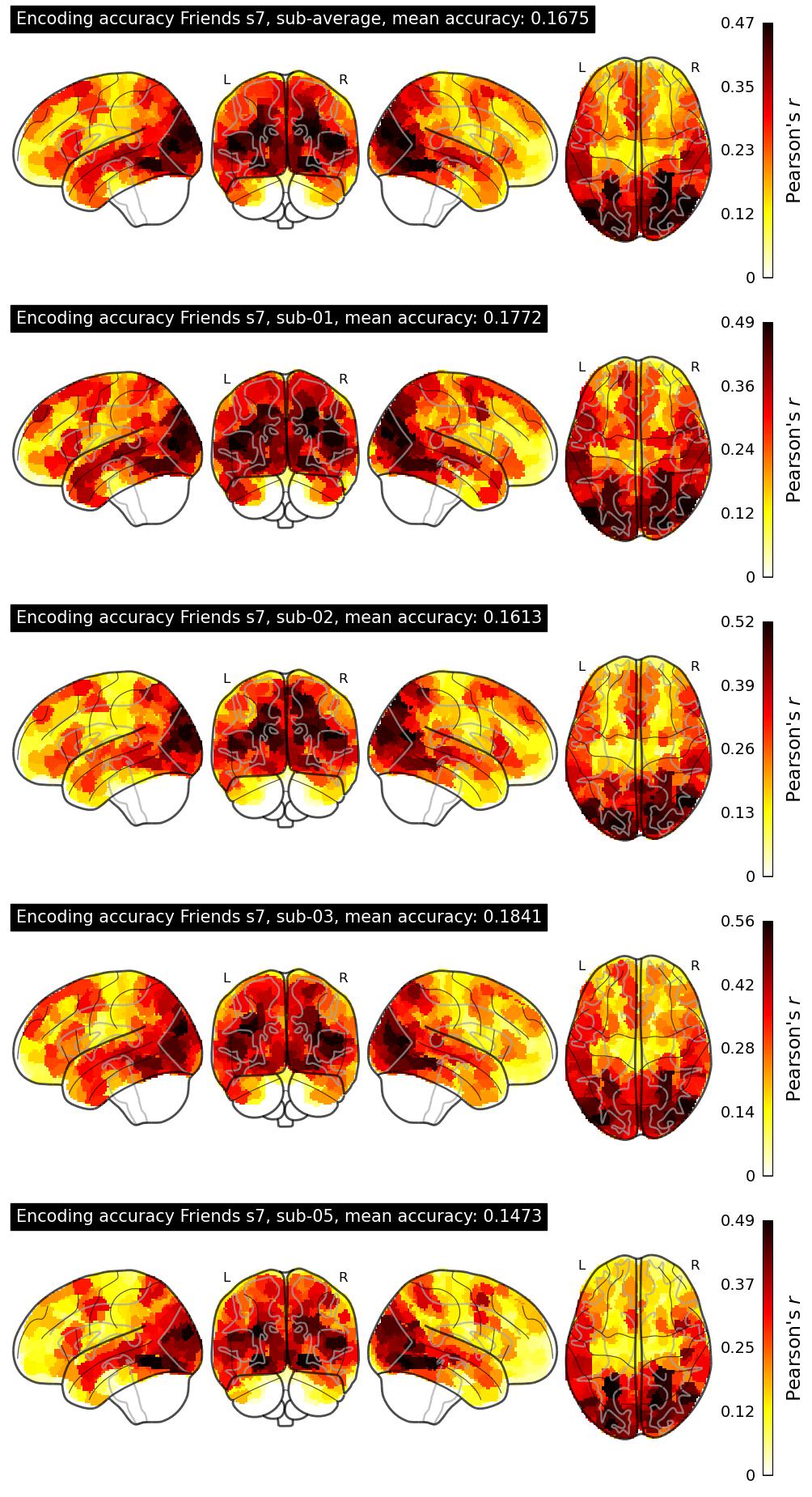
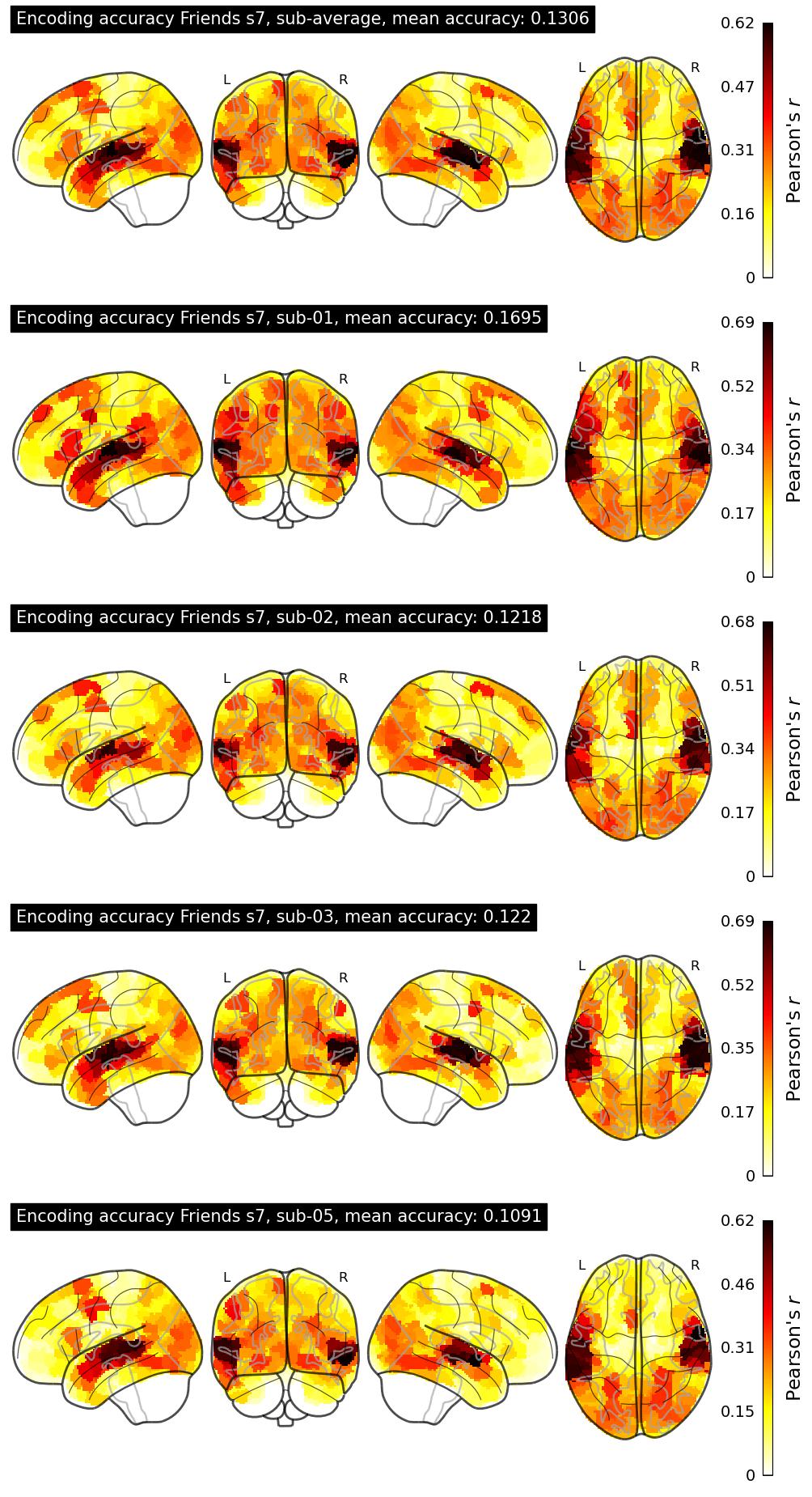
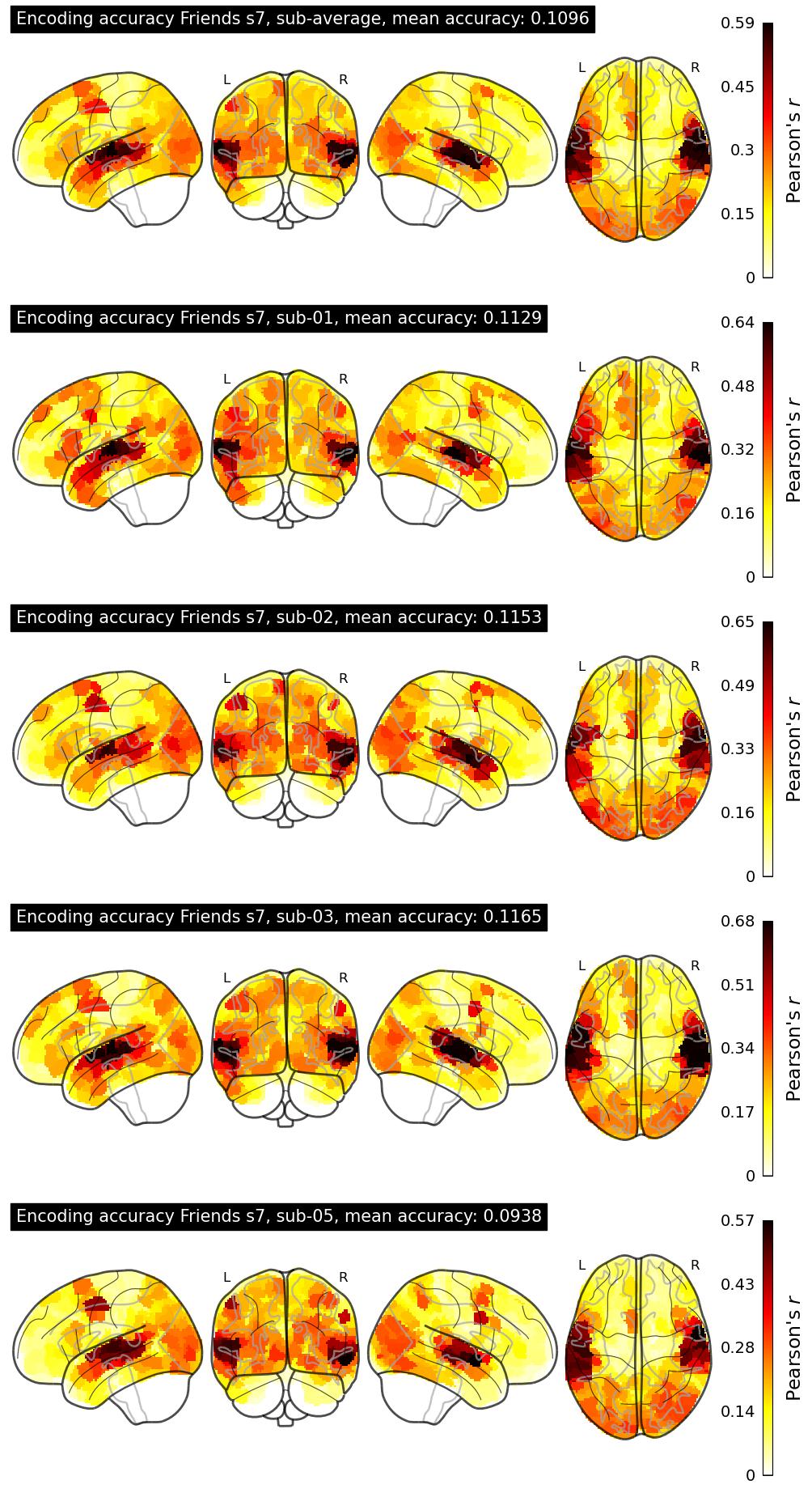
The Algonauts Project 2025 Challenge Model Building Phase leaderboard. The Challenge Score is the Pearson's correlation between predicted and withheld fMRI responses for Friends season 7, averaged across all brain parcels and subjects. View the leaderboard on Codabench here.
During this second phase, the winning models will be selected based on the accuracy of their predicted fMRI responses for withheld OOD movie stimuli.
| Rank | Team Name | Challenge Score | Report | Code | Visualization |
|---|---|---|---|---|---|
| 1 | sdascoli | 0.2146 | Visualization | ||
| 2 | NCG | 0.2096 | Visualization | ||
| 3 | SDA | 0.2094 | Visualization | ||
| 4 | ckadirt | 0.2085 | Visualization | ||
| 5 | CVIU-UARK | 0.2054 | Visualization | ||
| 6 | angelneer926 | 0.1986 | Visualization | ||
| 7 | ICL_SNU | 0.1612 | Visualization | ||
| 8 | corsi01 | 0.1576 | Visualization | ||
| 9 | alit | 0.1574 | Visualization | ||
| 10 | robertscholz | 0.1496 | Visualization | ||
| 11 | ryota1 | 0.1405 | Visualization | ||
| 12 | jeremywei | 0.1303 | Visualization | ||
| 13 | pcnlab | 0.1299 | Visualization | ||
| 14 | gabe_persson | 0.1276 | Visualization | ||
| 15 | viacheus | 0.1136 | Visualization | ||
| 16 | SJC | 0.1125 | Visualization | ||
| 17 | lio | 0.1066 | Visualization | ||
| 18 | DIO Research Lab - AUT | 0.1052 | Visualization | ||
| 19 | tinganli | 0.0969 | Visualization | ||
| 20 | hgz20 | 0.0921 | Visualization | ||
| 21 | baseline | 0.0895 | Visualization | ||
| 22 | mainak09 | 0.0889 | Visualization | ||
| 23 | killz | 0.0777 | Visualization | ||
| 24 | barbarioz | 0.0759 | Visualization | ||
| 25 | wangyt | 0.0542 | Visualization | ||
| 26 | nekopara | 0.0391 | Visualization | ||
| 27 | BOSSlab | 0.0253 | Visualization |
The Algonauts Project 2025 Challenge Model Selection Phase leaderboard. The Challenge Score is the Pearson’s correlation between predicted and withheld fMRI responses for the OOD movies, averaged across all brain parcels, movies, and subjects. View the leaderboard on Codabench here.
Once the challenge is over, we will open an indefinite post-challenge phase which will serve as a public benchmark. This benchmark will consist of two separate leaderboards that will rank encoding models based on their fMRI predictions for ID (Friends season 7) or OOD (OOD movies) multimodal movie stimuli, respectively.
To facilitate participation, we provide a development kit in Python which accompanies users through the challenge process, following four steps:
There are different ways to predict brain data using computational models. We put close to no restrictions on how you do so (see Challenge Rules). However, a commonly used approach is to use linearizing encoding models, and we provide a development kit to implement such a model.
1. Challenge participants can use any encoding model derived from any source and trained on any type of data. However, using recorded brain responses for Friends season 7 or the OOD movie stimuli is prohibited.
2. The winning models will be determined based on their performance in predicting fMRI responses for the OOD movie stimuli during the model selection phase.
3. Challenge participants can make an unlimited number of submissions during the model building phase, and a maximum of ten submissions during the model selection phase. Each challenge participant can only compete using one account. Creating multiple accounts to increase the number of possible submissions will result in disqualification to the challenge.
4. To promote open science, challenge participants who wish to be considered for the winners selection will need to submit a short report (~4-8 pages) describing their encoding algorithm to a preprint server (e.g. arXiv, bioRxiv), and send the PDF or preprint link to the Organizers by filling out this form. You must submit the challenge report by the challenge report submission deadline to be considered for the evaluation of the challenge outcome. Furthermore, while all reports are encouraged to link to their code (e.g. GitHub), the top-3 performing teams are required to make their code openly available. Participants that do not make their approach open and transparent cannot be considered. Along with monetary prizes, the top-3 performing teams will be invited to present their encoding models during a talk at the Cognitive Computational Neuroscience (CCN) conference held in Amsterdam (Netherlands) in August 2025.
| Challenge model building phase: | January 6th, 2025 to July 6th, 2025, at 00:00am (UTC-0) |
| Challenge model selection phase: | July 6th, 2025 to July 13th, 2025, at 00:00am (UTC-0) |
| Challenge report/code submission deadline: | July 25th, 2025 |
| Challenge results released:: | August 5th, 2025 |
| Session at CCN 2025: | August 13th, 2025, 10 am - 12 pm (UTC+2) |
If you participate in the challenge, use this form to submit the challenge report and code.
The Algonauts Project 2025 challenge is supported by German Research Council (DFG) grants (CI 241/1-3, CI 241/1-7, INST 272/297-1), the European Research Council (ERC) starting grant (ERC-StG-2018-803370), the German Research Foundation (DFG Research Unit FOR 5368 ARENA), Unifying Neuroscience and Artificial Intelligence - Québec (UNIQUE), and The Hessian Center for Artificial Intelligence. The Courtois project on neural modelling was made possible by a generous donation from the Courtois foundation, administered by the Fondation Institut Gériatrie Montréal at CIUSSS du Centre-Sud-de-l’île-de-Montréal and University of Montreal. The CNeuroMod data used in the Algonauts 2025 Challenge has been openly shared under a Creative Commons CC0 license by a subset of CNeuroMod participants through the Canadian Open Neuroscience Platform (CONP), funded by Brain Canada and based at McGill University, Canada.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}